Diffusion models took off like a rocket at the end of 2019, after the publication of Song & Ermon’s seminal paper. In this blog post, I highlight a connection to another type of model: the venerable autoencoder.
Diffusion models
Diffusion models are fast becoming the go-to model for any task that requires producing perceptual signals, such as images and sound. They provide similar fidelity as alternatives based on generative adversarial nets (GANs) or autoregressive models, but with much better mode coverage than the former, and a faster and more flexible sampling procedure compared to the latter.
In a nutshell, diffusion models are constructed by first describing a procedure for gradually turning data into noise, and then training a neural network that learns to invert this procedure step-by-step. Each of these steps consists of taking a noisy input and making it slightly less noisy, by filling in some of the information obscured by the noise. If you start from pure noise and do this enough times, it turns out you can generate data this way!
Diffusion models have been around for a while1, but really took off at the end of 20192. The ideas are young enough that the field hasn’t really settled on one particular convention or paradigm to describe them, which means almost every paper uses a slightly different framing, and often a different notation as well. This can make it quite challenging to see the bigger picture when trawling through the literature, of which there is already a lot! Diffusion models go by many names: denoising diffusion probabilistic models (DDPMs)3, score-based generative models, or generative diffusion processes, among others. Some people just call them energy-based models (EBMs), of which they technically are a special case.
My personal favourite perspective starts from the idea of score matching4 and uses a formalism based on stochastic differential equations (SDEs)5. For an in-depth treatment of diffusion models from this perspective, I strongly recommend Yang Song’s richly illustrated blog post (which also comes with code and colabs). It is especially enlightening with regards to the connection between all these different perspectives. If you are familiar with variational autoencoders, you may find Lilian Weng or Jakub Tomczak’s takes on this model family more approachable.
If you are curious about generative modelling in general, section 3 of my blog post on generating music in the waveform domain contains a brief overview of some of the most important concepts and model flavours.
Denoising autoencoders
Autoencoders are neural networks that are trained to predict their input. In and of itself, this is a trivial and meaningless task, but it becomes much more interesting when the network architecture is restricted in some way, or when the input is corrupted and the network has to learn to undo this corruption.
A typical architectural restriction is to introduce some sort of bottleneck, which limits the amount of information that can pass through. This implies that the network must learn to encode the most important information efficiently to be able to pass it through the bottleneck, in order to be able to accurately reconstruct the input. Such a bottleneck can be created by reducing the capacity of a particular layer of the network, by introducing quantisation (as in VQ-VAEs6) or by applying some form of regularisation to it during training (as in VAEs78 or contractive autoencoders9). The internal representation used in this bottleneck (often referred to as the latent representation) is what we are really after. It should capture the essence of the input, while discarding a lot of irrelevant detail.
Corrupting the input is another viable strategy to make autoencoders learn useful representations. One could argue that models with corrupted input are not autoencoders in the strictest sense, because the input and target output differ, but this is really a semantic discussion – one could just as well consider the corruption procedure part of the model itself. In practice, such models are typically referred to as denoising autoencoders.
Denoising autoencoders were actually some of the first true “deep learning” models: back when we hadn’t yet figured out how to reliably train neural networks deeper than a few layers with simple gradient descent, the prevalent approach was to pre-train networks layer by layer, and denoising autoencoders were frequently used for this purpose10 (especially by Yoshua Bengio and colleagues at MILA – restricted Boltzmann machines were another option, favoured by Geoffrey Hinton and colleagues).
One and the same?
So what is the link between modern diffusion models and these – by deep learning standards – ancient autoencoders? I was inspired to ponder this connection a bit more after seeing some recent tweets speculating about autoencoders making a comeback:
Are autoencoders making / going to make a comeback?
As far as I’m concerned, the autoencoder comeback is already in full swing, it’s just that we call them diffusion models now! Let’s unpack this.
The neural network that makes diffusion models tick is trained to estimate the so-called score function, \(\nabla_\mathbf{x} \log p(\mathbf{x})\), the gradient of the log-likelihood w.r.t. the input (a vector-valued function): \(\mathbf{s}_\theta (\mathbf{x}) = \nabla_\mathbf{x} \log p_\theta(\mathbf{x})\). Note that this is different from \(\nabla_\theta \log p_\theta(\mathbf{x})\), the gradient w.r.t. the model parameters \(\theta\), which is the one you would use for training if this were a likelihood-based model. The latter tells you how to change the model parameters to increase the likelihood of the input under the model, whereas the former tells you how to change the input itself to increase its likelihood. (This is the same gradient you would use for DeepDream-style manipulation of images.)
In practice, we want to use the same network at every point in the gradual denoising process, i.e. at every noise level (from pure noise all the way to clean data). To account for this, it takes an additional input \(t \in [0, 1]\) which indicates how far along we are in the denoising process: \(\mathbf{s}_\theta (\mathbf{x}_t, t) = \nabla_{\mathbf{x}_t} \log p_\theta(\mathbf{x}_t)\). By convention, \(t = 0\) corresponds to clean data and \(t = 1\) corresponds to pure noise, so we actually “go back in time” when denoising.
The way you train this network is by taking inputs \(\mathbf{x}\) and corrupting them with additive noise \(\mathbf{\varepsilon}_t \sim \mathcal{N}(0, \sigma_t^2)\), and then predicting \(\mathbf{\varepsilon}_t\) from \(\mathbf{x}_t = \mathbf{x} + \mathbf{\varepsilon}_t\). The reason why this works is not entirely obvious. I recommend reading Pascal Vincent’s 2010 tech report on the subject11 for an in-depth explanation of why you can do this.
Note that the variance depends on \(t\), because it corresponds to the specific noise level at time \(t\). The loss function is typically just mean squared error, sometimes weighted by a scale factor \(\lambda(t)\), so that some noise levels are prioritised over others:
Going forward, let’s assume \(\lambda(t) \equiv 1\), which is usually what is done in practice anyway (though other choices have their uses as well12).
One key observation is that predicting \(\mathbf{\varepsilon}_t\) or \(\mathbf{x}\) are equivalent, so instead, we could just use
To see that they are equivalent, consider taking a trained model \(\mathbf{s}_\theta\) that predicts \(\mathbf{\varepsilon}_t\) and add a new residual connection to it, going all the way from the input to the output, with a scale factor of \(-1\). This modified model then predicts:
In other words, we obtain a denoising autoencoder (up to a minus sign). This might seem surprising, but intuitively, it actually makes sense that to increase the likelihood of a noisy input, you should probably just try to remove the noise, because noise is inherently unpredictable. Indeed, it turns out that these two things are equivalent.
A tenuous connection?
Of course, the title of this blog post is intentionally a bit facetious: while there is a deeper connection between diffusion models and autoencoders than many people realise, the models have completely different purposes and so are not interchangeable.
There are two key differences with the denoising autoencoders of yore:
the additional input \(t\) makes one single model able to handle many different noise levels with a single set of shared parameters;
we care about the output of the model, not the internal latent representation, so there is no need for a bottleneck. In fact, it would probably do more harm than good.
In the strictest sense, both of these differences have no bearing on whether the model can be considered an autoencoder or not. In practice, however, the point of an autoencoder is usually understood to be to learn a useful latent representation, so saying that diffusion models are autoencoders could perhaps be considered a bit… pedantic. Nevertheless, I wanted to highlight this connection because I think many more people know the ins and outs of autoencoders than diffusion models at this point. I believe that appreciating the link between the two can make the latter less daunting to understand.
This link is not merely a curiosity, by the way; it has also been the subject of several papers, which constitute an early exploration of the ideas that power modern diffusion models. Apart from the work by Pascal Vincent mentioned earlier11, there is also a series of papers by Guillaume Alain and colleagues13 that14 are15 worth16 checking17 out18!
[Note that there is another way to connect diffusion models to autoencoders, by viewing them as (potentially infinitely) deep latent variable models. I am personally less interested in that connection because it doesn’t provide me with much additional insight, but it is just as valid. Here’s a blog post by Angus Turner that explores this interpretation in detail.]
Noise and scale
I believe the idea of training a single model to handle many different noise levels with shared parameters is ultimately the key ingredient that made diffusion models really take off. Song & Ermon2 called them noise-conditional score networks (NCSNs) and provide a very lucid explanation of why this is important, which I won’t repeat here.
The idea of using different noise levels in a single denoising autoencoder had previously been explored for representation learning, but not for generative modelling. Several works suggest gradually decreasing the level of noise over the course of training to improve the learnt representations192021. Composite denoising autoencoders22 have multiple subnetworks that handle different noise levels, which is a step closer to the score networks that we use in diffusion models, though still missing the parameter sharing.
A particularly interesting observation stemming from these works, which is also highly relevant to diffusion models, is that representations learnt using different noise levels tend to correspond to different scales of features: the higher the noise level, the larger-scale the features that are captured. I think this connection is worth investigating further: it implies that diffusion models fill in missing parts of the input at progressively smaller scales, as the noise level decreases step by step. This does seem to be the case in practice, and it is potentially a useful feature. Concretely, it means that \(\lambda(t)\) can be designed to prioritise the modelling of particular feature scales! This is great, because excessive attention to detail is actually a major problem with likelihood-based models (I’ve previously discussed this in more detail in section 6 of my blog post about typicality).
This connection between noise levels and feature scales was initially baffling to me: the noise \(\mathbf{\varepsilon}_t\) that we add to the input during training is isotropic Gaussian, so we are effectively adding noise to each input element (e.g. pixel) independently. If that is the case, how can the level of noise (i.e. the variance) possibly impact the scale of the features that are learnt? I found it helpful to think of it this way:
Let’s say we are working with images. Each pixel in an image that could be part of a particular feature (e.g. a human face) provides evidence for the presence (or absence) of that feature.
When looking at an image, we implicitly aggregate the evidence provided by all the pixels to determine which features are present (e.g. whether there is a face in the image or not).
Larger-scale features in the image will cover a larger proportion of pixels. Therefore, if a larger-scale feature is present in an image, there is more evidence pointing towards that feature.
Even if we add noise with a very high variance, that evidence will still be apparent, because when combining information from all pixels, we average out the noise.
If more pixels are involved in this process, the tolerable noise level increases, because the maximal variance that still allows for the noise to be canceled out is much higher. For smaller-scale features however, recovery will be impossible because the noise dominates when we can only aggregate information from a smaller set of pixels.
Concretely, if an image contains a human face and we add a lot of noise to it, we will probably no longer be able to discern the face if it is far away from the camera (i.e. covers fewer pixels in the image), whereas if it is close to the camera, we might still see a faint outline. The header image of this section provides another example: the level of noise decreases from left to right. On the very left, we can still see the rough outline of a mountain despite very high levels of noise.
This is completely handwavy, but it provides some intuition for why there is a direct correspondence between the variance of the noise and the scale of features captured by denoising autoencoders and score networks.
Closing thoughts
So there you have it: diffusion models are autoencoders. Sort of. When you squint a bit. Here are some key takeaways, to wrap up:
Learning to predict the score function \(\nabla_\mathbf{x} \log p(\mathbf{x})\) of a distribution can be achieved by learning to denoise examples of that distribution. This is a core underlying idea that powers modern diffusion models.
Compared to denoising autoencoders, score networks in diffusion models can handle all noise levels with a single set of parameters, and do not have bottlenecks. But other than that, they do the same thing.
Noise levels and feature scales are closely linked: high noise levels lead to models capturing large-scale features, low noise levels lead to models focusing on fine-grained features.
If you would like to cite this post in an academic context, you can use this BibTeX snippet:
@misc{dieleman2022diffusion,
author = {Dieleman, Sander},
title = {Diffusion models are autoencoders},
url = {https://benanne.github.io/2022/01/31/diffusion.html},
year = {2022}
}
Acknowledgements
Thanks to Conor Durkan and Katie Millican for fruitful discussions!
If you’re training or sampling from generative models, typicality is a concept worth understanding. It sheds light on why beam search doesn’t work for autoregressive models of images, audio and video; why you can’t just threshold the likelihood to perform anomaly detection with generative models; and why high-dimensional Gaussians are “soap bubbles”. This post is a summary of my current thoughts on the topic.
First, some context: one of the reasons I’m writing this, is to structure my own thoughts about typicality and the unintuitive behaviour of high-dimensional probability distributions. Most of these thoughts have not been empirically validated, and several are highly speculative and could be wrong. Please bear this in mind when reading, and don’t hesitate to use the comments section to correct me. Another reason is to draw more attention to the concept, as I’ve personally found it extremely useful to gain insight into the behaviour of generative models, and to correct some of my flawed intuitions. I tweeted about typicality a few months ago, but as it turns out, I have a lot more to say on the topic!
As with most of my blog posts, I will assume a degree of familiarity with machine learning. For certain parts, some knowledge of generative modelling is probably useful as well. Section 3 of my previous blog post provides an overview of generative models.
When it comes to generative modelling, my personal preference for the likelihood-based paradigm is no secret (my recent foray into adversarial methods for text-to-speech notwithstanding). While there are many other ways to build and train models (e.g. using adversarial networks, score matching, optimal transport, quantile regression, … see my previous blog post for an overview), there is something intellectually pleasing about the simplicity of maximum likelihood training: the model explicitly parameterises a probability distribution, and we fit the parameters of that distribution so it is able to explain the observed data as well as possible (i.e., assigns to it the highest possible likelihood).
It turns out that this is far from the whole story, and ‘higher likelihood’ doesn’t always mean better in a way that we actually care about. In fact, the way likelihood behaves in relation to the quality of a model as measured by humans (e.g. by inspecting samples) can be deeply unintuitive. This has been well-known in the machine learning community for some time, and Theis et al.’s A note on the evaluation of generative models1 does an excellent job of demonstrating this with clever thought experiments and concrete examples. In what follows, I will expound on what I think is going on when likelihoods disagree with our intuitions.
One particular way in which a higher likelihood can correspond to a worse model is through overfitting on the training set. Because overfitting is ubiquitous in machine learning research, the unintuitive behaviours of likelihood are often incorrectly ascribed to this phenomenon. In this post, I will assume that overfitting is not an issue, and that we are talking about properly regularised models trained on large enough datasets.
Motivating examples
Unfair coin flips
Jessica Yung has a great blog post that demonstrates how even the simplest of probability distributions start behaving in unintuitive ways in higher-dimensional spaces, and she links this to the concept of typicality. I will borrow her example here and expand on it a bit, but I recommend reading the original post.
To summarise: suppose you have an unfair coin that lands on heads 3 times out of 4. If you toss this coin 16 times, you would expect to see 12 heads (H) and 4 tails (T) on average. Of course you wouldn’t expect to see exactly 12 heads and 4 tails every time: there’s a pretty good chance you’d see 13 heads and 3 tails, or 11 heads and 5 tails. Seeing 16 heads and no tails would be quite surprising, but it’s not implausible: in fact, it will happen about 1% of the time. Seeing all tails seems like it would be a miracle. Nevertheless, each coin toss is independent, so even this has a non-zero probability of being observed.
When we count the number of heads and tails in the observed sequence, we’re looking at the binomial distribution. We’ve made the implicit assumption that what we care about is the frequency of occurrence of both outcomes, and not the order in which they occur. We’ve made abstraction of the order, and we are effectively treating the sequences as unordered sets, so that HTHHTHHHHTTHHHHH and HHHHHTHTHHHTHTHH are basically the same thing. That is often desirable, but it’s worth being aware of such assumptions, and making them explicit.
If we do not ignore the order, and ask which sequence is the most likely, the answer is ‘all heads’. That may seem surprising at first, because seeing only heads is a relatively rare occurrence. But note that we’re asking a different question here, about the ordered sequences themselves, rather than about their statistics. While the difference is pretty clear here, the implicit assumptions and abstractions that we tend to use in our reasoning are often more subtle.
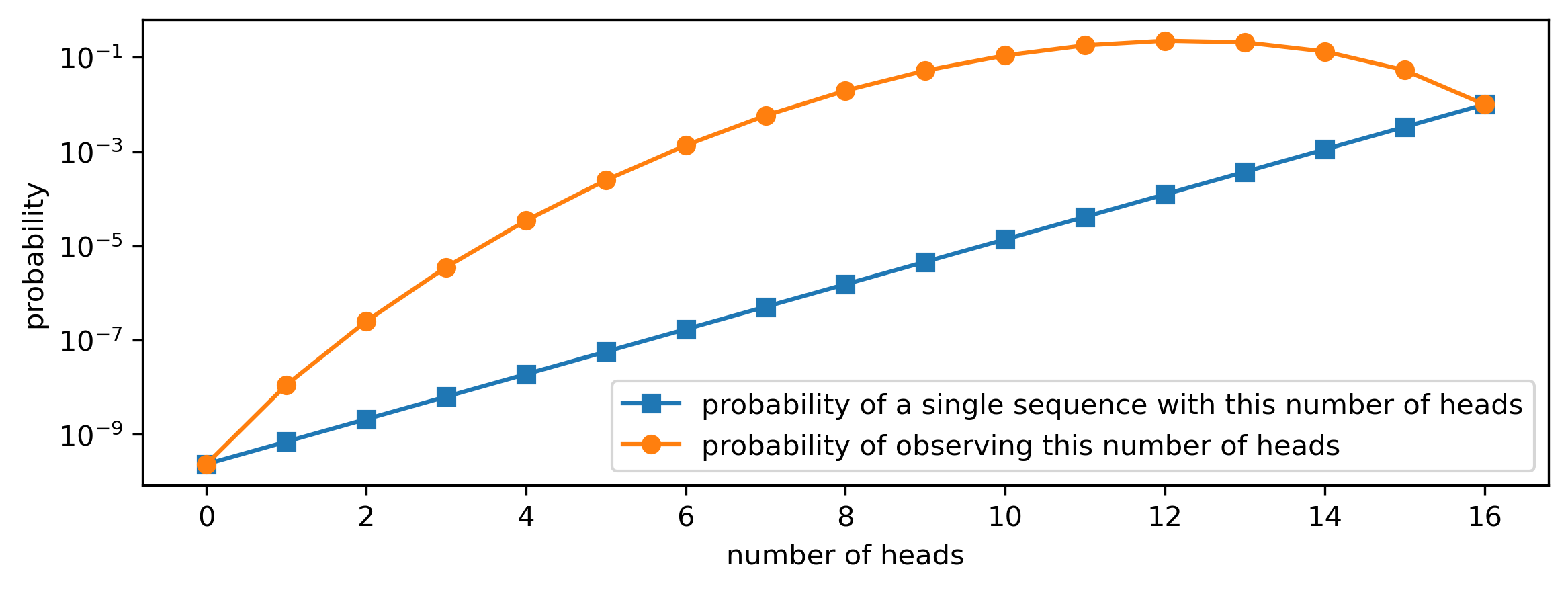
The table and figure below show how the probability of observing a given number of heads and tails can be found by multiplying the probability of a particular sequence with the number of such sequences. Note that ‘all heads’ has the highest probability out of all sequences (bolded), but there is only a single such sequence. The most likely number of heads we’ll observe is 12 (also bolded): even though each individual sequence with 12 heads is less likely, there are a lot more of them, and this second factor ends up dominating.
importmatplotlib.pyplotaspltimportnumpyasnpimportscipy.specialh=np.arange(16+1)p_sequence=(3/4)**h*(1/4)**(16-h)num_sequences=scipy.special.comb(16,h)p_heads_count=p_sequence*num_sequencesplt.figure(figsize=(9,3))plt.plot(h,p_sequence,'C0-s',label='probability of a single sequence with this number of heads')plt.plot(h,p_heads_count,'C1-o',label='probability of observing this number of heads')plt.yscale('log')plt.xlabel('number of heads')plt.ylabel('probability')plt.legend()
Probabilities of observing a particular sequence with a given number of heads, and of observing a given number of heads.
Gaussian soap bubbles
Another excellent blog post about the unintuitive behaviour of high-dimensional probability distributions is Ferenc Huszar’s ‘Gaussian Distributions are Soap Bubbles’. A one-dimensional Gaussian looks like bell curve: a big bump around the mode, with a tail on either side. Clearly, the bulk of the total probability mass is clumped together around the mode. In higher-dimensional spaces, this shape changes completely: the bulk of the probability mass of a spherical Gaussian distribution with unit variance in \(K\) dimensions is concentrated in a thin ‘shell’ at radius \(\sqrt{K}\). This is known as the Gaussian annulus theorem.
For example, if we sample lots of vectors from a 100-dimensional standard Gaussian, and measure their radii, we will find that just over 84% of them are between 9 and 11, and more than 99% are between 8 and 12. Only about 0.2% have a radius smaller than 8!
Ferenc points out an interesting implication: high-dimensional Gaussians are very similar to uniform distributions on the sphere. This clearly isn’t true for the one-dimensional case, but it turns out that’s an exception, not the rule. Stefan Stein also discusses this implication in more detail in a recent blog post.
Where our intuition can go wrong here, is that we might underestimate how quickly a high-dimensional space grows in size as we move further away from the mode. Because of the radial symmetry of the distribution, we tend to think of all points at a given distance from the mode as similar, and we implicitly group them into sets of concentric spheres. This allows us to revert back to reasoning in one dimension, which we are more comfortable with: we think of a high-dimensional Gaussian as a distribution over these sets, rather than over individual points. What we tend to overlook, is that those sets differ wildly in size: as we move away from the mode, they grow larger very quickly. Note that this does not happen at all in 1D!
Abstraction and the curse of dimensionality
The curse of dimensionality is a catch-all term for various phenomena that appear very different and often counterintuitive in high-dimensional spaces. It is used to highlight poor scaling behaviour of ideas and algorithms, where one wouldn’t necessarily expect it. In the context of machine learning, it is usually used in a more narrow sense, to refer to the fact that models of high-dimensional data tend to require very large training datasets to be effective. But the curse of dimensionality manifests itself in many forms, and the unintuitive behaviour of high-dimensional probability distributions is just one of them.
In general, humans have lousy intuitions about high-dimensional spaces. But what exactly is going on when we get things wrong about high-dimensional distributions? In both of the motivating examples, the intuition breaks down in a similar way: if we’re not careful, we might implicitly reason about the probabilities of sets, rather than individual points, without taking into account their relative sizes, and arrive at the wrong answer. This means that we can encounter this issue for both discrete and continuous distributions.
We can generalise this idea of grouping points into sets of similar points, by thinking of it as ‘abstraction’: rather than treating each point as a separate entity, we think of it as an instance of a particular concept, and ignore its idiosyncrasies. When we think of ‘sand’, we are rarely concerned about the characteristics of each individual grain. Similarly, in the ‘unfair coin flips’ example, we group sequences by their number of heads and tails, ignoring their order. In the case of the high-dimensional Gaussian, the natural grouping of points is based on their Euclidean distance from the mode. A more high-level example is that of natural images, where individual pixel values across localised regions of the image combine to form edges, textures, or even objects. There are usually many combinations of pixel values that give rise to the same texture, and we aren’t able to visually distinguish these particular instances unless we carefully study them side by side.
The following is perhaps a bit of an unfounded generalisation based on my own experience, but our brains seem hardwired to perform this kind of abstraction, so that we can reason about things in the familiar low-dimensional setting. It seems to happen unconsciously and continuously, and bypassing it requires a proactive approach.
Typicality
Informally, typicality refers to the characteristics that samples from a distribution tend to exhibit on average (in expectation). In the ‘unfair coin flip’ example, a sequence with 12 heads and 4 tails is ‘typical’. A sequence with 6 heads and 10 tails is highly atypical. Typical sequences contain an average amount of information: they are not particularly surprising or (un)informative.
We can formalise this intuition using the entropy of the distribution: a typical set \(\mathcal{T}_\varepsilon \subset \mathcal{X}\) is a set of sequences from \(\mathcal{X}\) whose probability is close to \(2^{-H}\), where \(H\) is the entropy of the distribution that the sequences were drawn from, measured in bits:
This means that the negative log likelihood of each such sequence is close to the entropy. Note that a distribution doesn’t have just one typical set: we can define many typical sets based on how close the probability of the sequences contained therein should be to \(2^{-H}\), by choosing different values of \(\varepsilon > 0\).
This concept was originally defined in an information-theoretic context, but I want to focus on machine learning, where I feel it is somewhat undervalued. It is often framed in terms of sequences sampled from stationary ergodic processes, but it is useful more generally for distributions of any kind of high-dimensional data points, both continuous and discrete, regardless of whether we tend to think of them as sequences.
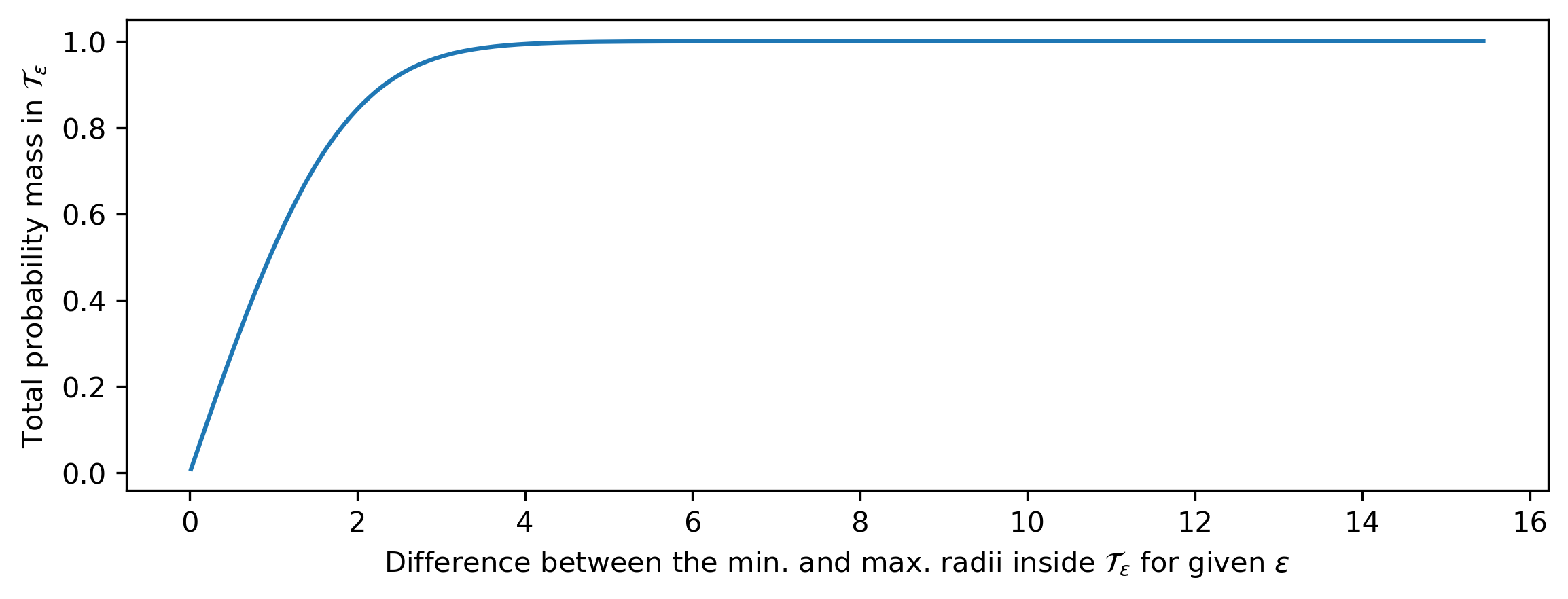
Why is this relevant to our discussion of abstraction and flawed human intuitions? As the dimensionality increases, the probability that any random sample from a distribution is part of a given typical set \(\mathcal{T}_\varepsilon\) tends towards 1. In other words, randomly drawn samples will almost always be ‘typical’, and the typical set covers most of the support of the distribution (this is a consequence of the so-called asymptotic equipartition property (AEP)). This happens even when \(\varepsilon\) is relatively small, as long as the dimensionality is high enough. This is visualised for a 100-dimensional standard Gaussian distribution below (based on empirical measurements, to avoid having to calculate some gnarly 100D integrals).
importmatplotlib.pyplotaspltimportnumpyasnpN=1000000K=100samples=np.random.normal(0,1,(N,K))radii=np.sqrt(np.sum(samples**2,axis=-1))epsilon=np.logspace(-1,2,200)lo=np.sqrt(np.maximum(K-epsilon*np.log(4),0))hi=np.sqrt(K+epsilon*np.log(4))radius_range=hi-lomass=[np.mean((lo[i]<radii)&(radii<hi[i]))foriinrange(len(epsilon))]plt.figure(figsize=(9,3))plt.plot(radius_range,mass)plt.xlabel('Difference between the min. and max. radii inside ''$\\mathcal{T}_\\varepsilon$ for given $\\varepsilon$')plt.ylabel('Total probability mass in $\\mathcal{T}_\\varepsilon$')
The total probability mass of a range of typical sets of a 100-dimensional standard Gaussian distribution, with their size measured by the difference between the minimal and maximal radii within the set (i.e. the width of the Gaussian annulus). An annulus with width 4 already contains most of the probability mass.
But this is where it gets interesting: for unimodal high-dimensional distributions, such as the multivariate Gaussian, the mode (i.e. the most likely value) usually isn’t part of the typical set. More generally, individual samples from high-dimensional (and potentially multimodal) distributions that have an unusually high likelihood are not typical, so we wouldn’t expect to see them when sampling. This can seem paradoxical, because they are by definition very ‘likely’ samples — it’s just that there are so few of them! Think about how surprising it would be to randomly sample the zero vector (or something very close to it) from a 100-dimensional standard Gaussian distribution.
This has some important implications: if we want to learn more about what a high-dimensional distribution looks like, studying the most likely samples is usually a bad idea. If we want to obtain a good quality sample from a distribution, subject to constraints, we should not be trying to find the single most likely one. Yet in machine learning, these are things that we do on a regular basis. In the next section, I’ll discuss a few situations where this paradox comes up in practice. For a more mathematical treatment of typicality and the curse of dimensionality, check out this case study by Bob Carpenter.
Typicality in the wild
A significant body of literature, spanning several subfields of machine learning, has sought to interpret and/or mitigate the unintuitive ways in which high-dimensional probability distributions behave. In this section, I want to highlight a few interesting papers and discuss them in relation to the concept of typicality. Note that I’ve made a selection based on what I’ve read recently, and this is not intended to be a comprehensive overview of the literature. In fact, I would appreciate pointers to other related work (papers and blog posts) that I should take a look at!
Language modelling
In conditional language modelling tasks, such as machine translation or image captioning, it is common to use conditional autoregressive models in combination with heuristic decoding strategies such as beam search. The underlying idea is that we want to find the most likely sentence (i.e. the mode of the conditional distribution, ‘MAP decoding’), but since this is intractable, we’ll settle for an approximate result instead.
With typicality in mind, it’s clear that this isn’t necessarily the best idea. Indeed, researchers have found that machine translation results, measured using the BLEU metric, sometimes get worse when the beam width is increased23. A higher beam width gives a better, more computationally costly approximation to the mode, but not necessarily better translation results. In this case, it’s tempting to blame the metric itself, which obviously isn’t perfect, but this effect has also been observed with human ratings4, so that cannot be the whole story.
A recent paper by Eikema & Aziz5 provides an excellent review of recent work in this space, and makes a compelling argument for MAP decoding as the culprit behind many of the pathologies that neural machine translation systems exhibit (rather than their network architectures or training methodologies). They also propose an alternative decoding strategy called ‘minimum Bayes risk’ (MBR) decoding that takes into account the whole distribution, rather than only the mode.
In unconditional language modelling, beam search hasn’t caught on, but not for want of trying! Stochasticity of the result is often desirable in this setting, and the focus has been on sampling strategies instead. In The Curious Case of Neural Text Degeneration6, Holtzman et al. observe that maximising the probability leads to poor quality results that are often repetitive. Repetitive samples may not be typical, but they have high likelihoods simply because they are more predictable.
They compare a few different sampling strategies that interpolate between fully random sampling and greedy decoding (i.e. predicting the most likely token at every step in the sequence), including the nucleus sampling technique which they propose. The motivation for trying to find a middle ground is that models will assign low probabilities to sequences that they haven’t seen much during training, which makes low-probability predictions inherently less reliable. Therefore, we want to avoid sampling low-probability tokens to some extent.
Zhang et al.4 frame the choice of a language model decoding strategy as a trade-off between diversity and quality. However, they find that reducing diversity only helps quality up to a point, and reducing it too much makes the results worse, as judged by human evaluators. They call this ‘the likelihood trap’: human-judged quality of samples correlates very well with likelihood, up to an inflection point, where the correlation becomes negative.
In the context of typicality, this raises an interesting question: where exactly is this inflection point, and how does it relate to the typical set of the model distribution? I think it would be very interesting to determine whether the inflection point coincides exactly with the typical set, or whether it is more/less likely. Perhaps there is some degree of atypicality that human raters will tolerate? If so, can we quantify it? This wouldn’t be far-fetched: think about our preference for celebrity faces over ‘typical’ human faces, for example!
Image modelling
The previously mentioned ‘note on the evaluation of generative models’1 is a seminal piece of work that demonstrates several ways in which likelihoods in the image domain can be vastly misleading.
In ‘Do Deep Generative Models Know What They Don’t Know?’7, Nalisnick et al. study the behaviour of likelihood-based models when presented with out-of-domain data. They observe how models can assign higher likelihoods to datasets other than their training datasets. Crucially, they show this for different classes of likelihood-based models (variational autoencoders, autoregressive models and flow-based models, see Figure 3 in the paper), which clearly demonstrates that this is an issue with the likelihood-based paradigm itself, and not with a particular model architecture or formulation.
Comparing images from CIFAR-10 and SVHN, two of the datasets they use, a key difference is the prevalence of textures in CIFAR-10 images, and the relative absence of such textures in SVHN images. This makes SVHN images inherently easier to predict, which partially explains why models trained on CIFAR-10 tend to assign higher likelihoods to SVHN images. Despite this, we clearly wouldn’t ever be able to sample anything that looks like an SVHN image from a CIFAR-10-trained model, because such images are not in the typical set of the model distribution (even if their likelihood is higher).
Audio modelling
I don’t believe I’ve seen any recent work that studies sampling and decoding strategies for likelihood-based models in the audio domain. Nevertheless, I wanted to briefly discuss this setting because a question I often get is: “why don’t you use greedy decoding or beam search to improve the quality of WaveNet samples?”
If you’ve read this far, the answer is probably clear to you by now: because audio samples outside of the typical set sound really weird! In fact, greedy decoding from a WaveNet will invariably yield complete silence, even for fairly strongly conditioned models (e.g. WaveNets for text-to-speech synthesis). In the text-to-speech case, even if you simply reduce the sampling temperature a bit too aggressively, certain consonants that are inherently noisy (such as ‘s’, ‘f’, ‘sh’ and ‘h’, the fricatives) will start sounding very muffled. These sounds are effectively different kinds of noise, and reducing the stochasticity of this noise has an audible effect.
Anomaly detection
Anomaly detection, or out-of-distribution (OOD) detection, is the task of identifying whether a particular input could have been drawn from a given distribution. Generative models are often used for this purpose: train an explicit model on in-distribution data, and then use its likelihood estimates to identify OOD inputs.
Usually, the assumption is made that OOD inputs will have low likelihoods, and in-distribution inputs will have high likelihoods. However, the fact that the mode of a high-dimensional distribution usually isn’t part of its typical set clearly contradicts this. This mistaken assumption is quite pervasive. Only recently has it started to be challenged explicitly, e.g. in works by Nalisnick et al.8 and Morningstar et al.9. Both of these works propose testing the typicality of inputs, rather than simply measuring and thresholding their likelihood.
The right level of abstraction
While our intuitive notion of likelihood in high-dimensional spaces might technically be wrong, it can often be a better representation of what we actually care about. This raises the question: should we really be fitting our generative models using likelihood measured in the input space? If we were to train likelihood-based models with ‘intuitive’ likelihood, they might perform better according to perceptual metrics, because they do not have to waste capacity capturing all the idiosyncrasies of particular examples that we don’t care to distinguish anyway.
In fact, measuring likelihood in more abstract representation spaces has had some success in generative modelling, and I think the approach should be taken more seriously in general. In language modelling, it is common to measure likelihoods at the level of word pieces, rather than individual characters. In symbolic music modelling, recent models that operate on event-based sequences (rather than sequences with a fixed time quantum) are more effective at capturing large-scale structure10. Some likelihood-based generative models of images separate or discard the least-significant bits of each pixel colour value, because they are less perceptually relevant, allowing model capacity to be used more efficiently1112.
But perhaps the most striking example is the recent line of work where VQ-VAE13 is used to learn discrete higher-level representations of perceptual signals, and generative models are then trained to maximise the likelihood in this representation space. This approach has led to models that produce images that are on par with those produced by GANs in terms of fidelity, and exceed them in terms of diversity141516. It has also led to models that are able to capture long-range temporal structure in audio signals, which even GANs had not been able to do before1718. While the current trend in representation learning is to focus on coarse-grained representations which are suitable for discriminative downstream tasks, I think it also has a very important role to play in generative modelling.
In the context of modelling sets with likelihood-based models, a recent blog post by Adam Kosiorek drew my attention to point processes, and in particular, to the formula that expresses the density over ordered sequences in terms of the density over unordered sets. This formula quantifies how we need to scale probabilities across sets of different sizes to make them comparable. I think it may yet prove useful to quantify the unintuitive behaviours of likelihood-based models.
Closing thoughts
To wrap up this post, here are some takeaways:
High-dimensional spaces, and high-dimensional probability distributions in particular, are deeply unintuitive in more ways than one. This is a well-known fact, but they still manage to surprise us sometimes!
The most likely samples from a high-dimensional distribution usually aren’t a very good representation of that distribution. In most situations, we probably shouldn’t be trying to find them.
Typicality is a very useful concept to describe these unintuitive phenomena, and I think it is undervalued in machine learning — at least in the work that I’ve been exposed to.
A lot of work that discusses these issues (including some that I’ve highlighted in this post) doesn’t actually refer to typicality by name. I think doing so would improve our collective understanding, and shed light on links between related phenomena in different subfields.
If you have any thoughts about this topic, please don’t hesitate to share them in the comments below!
In an addendum to this post, I explore quantitatively what happens when our intuitions fail us in high-dimensional spaces.
If you would like to cite this post in an academic context, you can use this BibTeX snippet:
@misc{dieleman2020typicality,
author = {Dieleman, Sander},
title = {Musings on typicality},
url = {https://benanne.github.io/2020/09/01/typicality.html},
year = {2020}
}
Acknowledgements
Thanks to Katie Millican, Jeffrey De Fauw and Adam Kosiorek for their valuable input and feedback on this post!
This post is an addendum to my blog post about typicality. Please consider reading that first, if you haven’t already. Here, I will try to quantify what happens when our intuitions fail us in high-dimensional spaces.
Note that the practical relevance of this is limited, so consider this a piece of optional extra content!
In the ‘unfair coin flips’ example from the main blog post, it’s actually pretty clear what happens when our intuitions fail us: we think of the binomial distribution, ignoring the order of the sequences as a factor, when we should actually be taking it into account. Referring back to the table from section 2.1, we use the probabilities in the rightmost column, when we should be using those in the third column. But when we think of a high-dimensional Gaussian distribution and come to the wrong conclusion, what distribution are we actually thinking of?
The Gaussian distribution \(\mathcal{N}_K\)
Let’s start by quantifying what a multivariate Gaussian distribution actually looks like: let \(\mathbf{x} \sim \mathcal{N}(\mathbf{0}, I_K)\), a standard Gaussian distribution in \(K\) dimensions, henceforth referred to as \(\mathcal{N}_K\). We can sample from it by drawing \(K\) independent one-dimensional samples \(x_i \sim \mathcal{N}(0, 1)\), and joining them into a vector \(\mathbf{x}\). This distribution is spherically symmetric, which makes it very natural to think about samples in terms of their distance to the mode (in this case, the origin, corresponding to the zero-vector \(\mathbf{0}\)), because all samples at a given distance \(r\) have the same density.
Now, let’s look at the distribution of \(r\): it seems as if the multivariate Gaussian distribution \(\mathcal{N}_K\) naturally arises by taking a univariate version of it, and rotating it around the mode in every possible direction in \(K\)-dimensional space. Because each of these individual rotated copies is Gaussian, this in turn might seem to imply that the distance from the mode \(r\) is itself Gaussian (or rather half-Gaussian, since it is a nonnegative quantity). But this is incorrect! \(r\) actually follows a chi distribution with \(K\) degrees of freedom: \(r \sim \chi_K\).
Note that for \(K = 1\), this does indeed correspond to a half-Gaussian distribution. But as \(K\) increases, the mode of the chi distribution rapidly shifts away from 0: it actually sits at \(\sqrt{K - 1}\). This leaves considerably less probability mass near 0, where the mode of our original multivariate Gaussian \(\mathcal{N}_K\) is located.
This exercise yields an alternative sampling strategy for multivariate Gaussians: first, sample a distance from the mode \(r \sim \chi_K\). Then, sample a direction, i.e. a vector on the \(K\)-dimensional unit sphere \(S^K\), uniformly at random: \(\mathbf{\theta} \sim U[S^K]\). Multiply them together to obtain a Gaussian sample: \(\mathbf{x} = r \cdot \mathbf{\theta} \sim \mathcal{N}_K\).
The Gaussian mirage distribution \(\mathcal{M}_K\)
What if, instead of sampling \(r \sim \chi_K\), we sampled \(r \sim \mathcal{N}(0, K)\) instead? Note that \(\sigma^2_{\chi_K} = K\), so this change preserves the scale of the resulting vectors. For \(K = 1\), we get the same distribution for \(\mathbf{x}\), but for \(K > 1\), we get something very different. The resulting distribution represents what we might think the multivariate Gaussian distribution looks like, if we rely on a mistaken intuition and squint a bit. Let’s call this the Gaussian mirage distribution, denoted by \(\mathcal{M}\): \(\mathbf{x} = r \cdot \mathbf{\theta} \sim \mathcal{M}_K\). (If this thing already has a name, I’m not aware of it, so please let me know!)
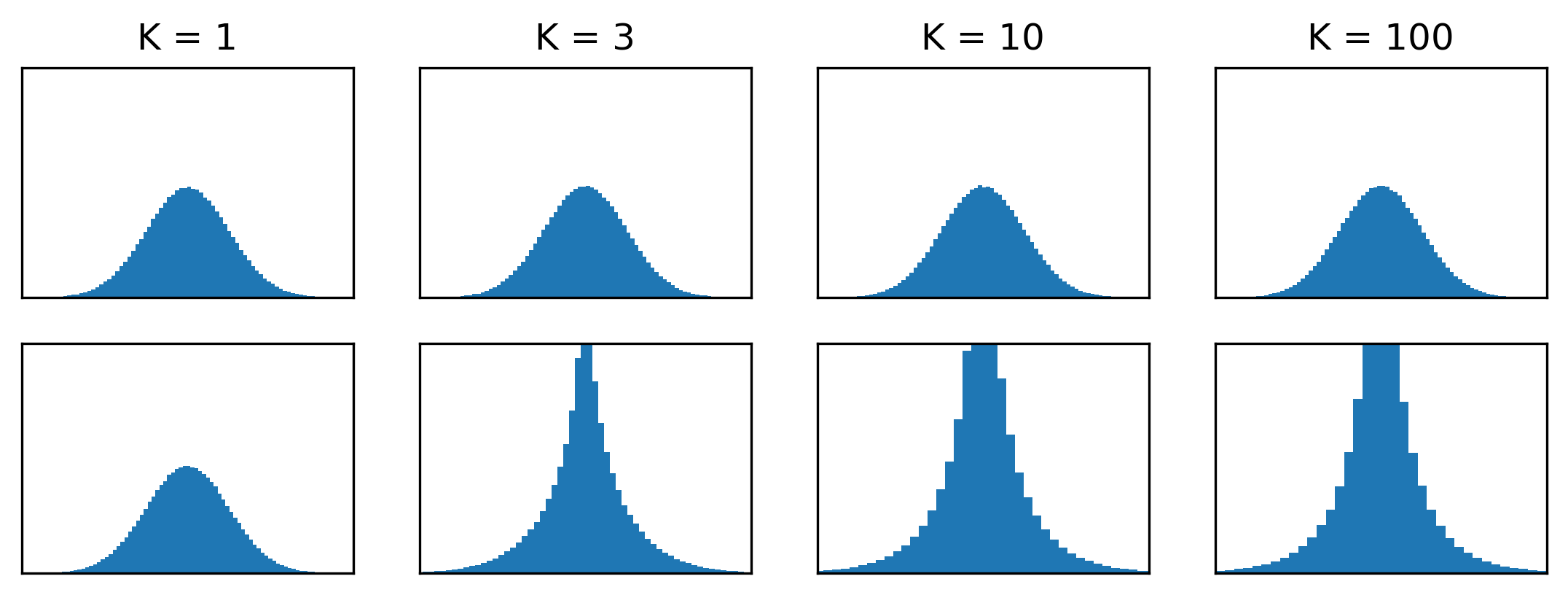
We’ve already established that \(\mathcal{M}_1 \equiv \mathcal{N}_1\). But in higher dimensions, these distributions behave very differently. One way to comprehend this is to look at a flattened histogram of samples across all coordinates:
Histograms of the flattened coordinates of the multivariate Gaussian distribution (top) and the Gaussian mirage (bottom), for different dimensionalities (K). For the mirage, the histograms become increasingly peaked around 0 as the dimensionality increases.
For \(\mathcal{N}_K\), this predictably looks like a univariate Gaussian for all \(K\). For \(\mathcal{M}_K\), it becomes highly leptokurtic as \(K\) increases, indicating that dramatically more probability mass is located close to the mode.
Typical sets of \(\mathcal{N}_K\) and \(\mathcal{M}_K\)
Let’s also look at the typical sets for both of these distributions. For \(\mathcal{N}_K\), the probability density function (pdf) has the form:
\[H_{\mathcal{N}_K} = \frac{K}{2} \log \left(2 \pi e \right) .\]
To find the typical set, we just need to look for the \(\mathbf{x}\) where \(f_{\mathcal{N}_K}(\mathbf{x}) \approx 2^{-H_{\mathcal{N}_K}} = (2 \pi e)^{-\frac{K}{2}}\) (assuming the entropy is measured in bits). This is clearly the case when \(\mathbf{x}^T\mathbf{x} \approx K\), or in other words, for any \(\mathbf{x}\) whose distance from the mode is close to \(\sqrt{K}\). This is the Gaussian annulus from before.
Let’s subject the Gaussian mirage \(\mathcal{M}_K\) to the same treatment. It’s not obvious how to express the pdf in terms of \(\mathbf{x}\), but it’s easier if we rewrite \(\mathbf{x}\) as \(r \cdot \mathbf{\theta}\), as before, and imagine the sampling procedure: first, pick a radius \(r \sim \mathcal{HN}(0, K)\) (the half-Gaussian distribution — using the Gaussian distribution complicates the math a bit, because the radius should be nonnegative), and then pick a position on the \(K\)-sphere with radius \(r\), uniformly at random:
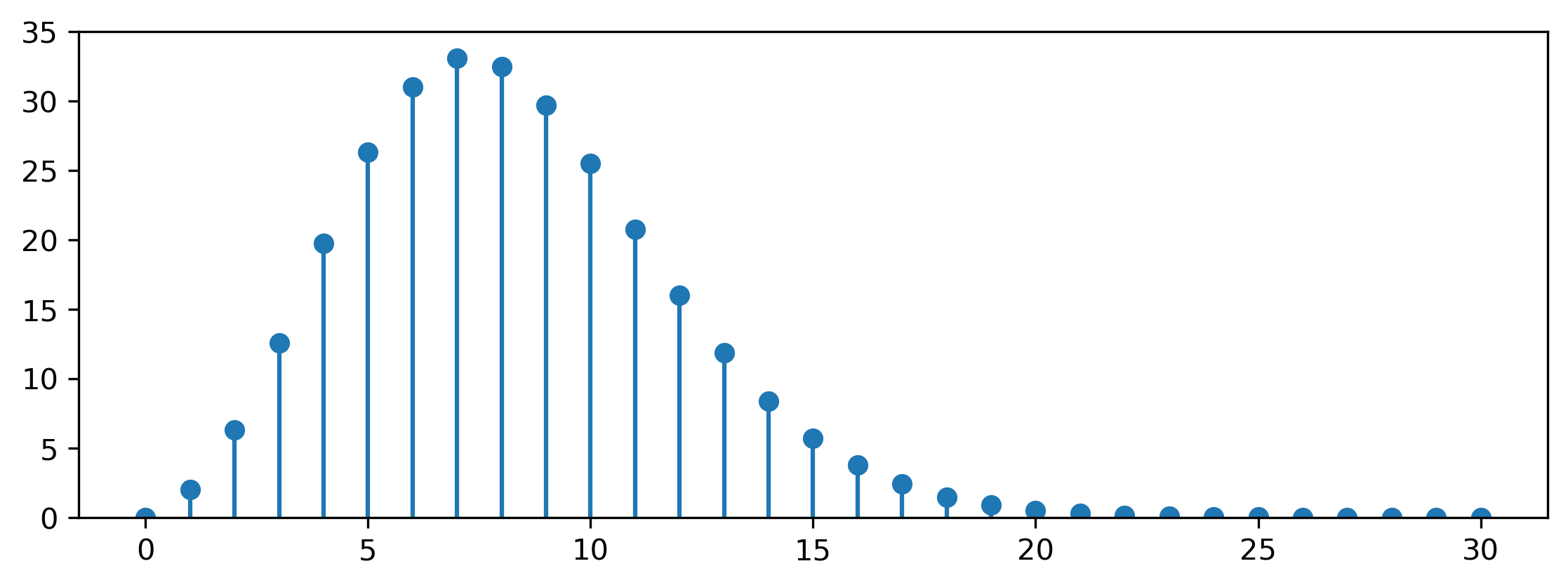
The former factor is the density of the half-Gaussian distribution: note the additional factor 2 compared to the standard Gaussian density, because we only consider nonnegative values of \(r\). The latter is the density of a uniform distribution on the \(K\)-sphere with radius \(r\) (which is the inverse of its surface area). As an aside, this factor is worth taking a closer look at, because it behaves in a rather peculiar way. Here’s the surface area of a unit \(K\)-sphere for increasing \(K\):
Surface area of a K-dimensional unit sphere, for K ranging from 0 to 30.
Confused? You and me both! Believe it or not, the surface area of a \(K\)-sphere tends to zero with increasing \(K\) — but only after growing to a maximum at \(K = 7\) first. High-dimensional spaces are weird.
Another thing worth noting is that the density at the mode \(f_{\mathcal{M}_K}(\mathbf{0}) = +\infty\) for \(K > 1\), which already suggests that this distribution has a lot of its mass concentrated near the mode.
Computing the entropy of this distribution takes a bit of work. The differential entropy is:
where we have made use of the fact that \(S^K(r)\) cancels out with the second factor of \(f_{\mathcal{M}_K}(r)\). We can split up the \(\log\) into three different terms, \(H_{\mathcal{M}_K} = H_1 + H_2 + H_3\):
Note that \(H_{\mathcal{M}_1} = \frac{1}{2} \log (2 \pi e)\), matching the standard Gaussian distribution as expected.
Because this is measured in nats, not in bits, we find the typical set where \(f_{\mathcal{M}_K}(\mathbf{x}) \approx \exp(-H_{\mathcal{M}_K})\). We must find \(r \geq 0\) so that
importmatplotlib.pyplotaspltimportnumpyasnpimportscipy.specialK=np.unique(np.round(np.logspace(0,6,100)))w_arg=np.exp(1/(K-1)+np.log(K/2)-np.euler_gamma)/(K*(K-1))r=np.sqrt(K*(K-1)*scipy.special.lambertw(w_arg))r[0]=1# Special case for K = 1.
plt.figure(figsize=(9,3))plt.plot(K,r/np.sqrt(K))plt.xscale('log')plt.ylim(0,1.2)plt.xlabel('$K$')plt.ylabel('$\\frac{r}{\\sqrt{K}}$')
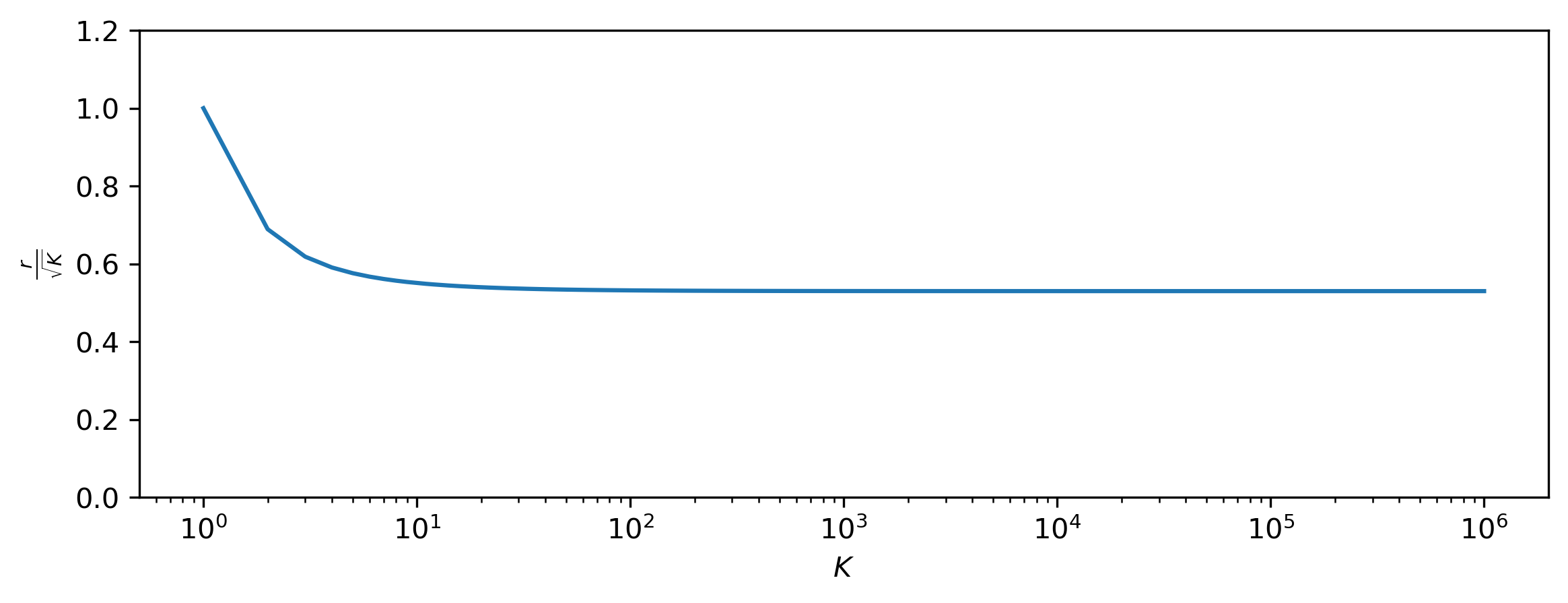
The distance from the mode at which the typical set of the Gaussian mirage is found, normalised by the standard deviation, as a function of K.
As \(K \to +\infty\), this seems to converge to the value \(0.52984 \sqrt{K}\), which is somewhere in between the mode (\(0\)) and the mean (\(\sqrt{\frac{2K}{\pi}} \approx 0.79788 \sqrt{K}\)) of the half-Gaussian distribution (which \(r\) follows by construction). This is not just an interesting curiosity: although it is clear that the typical set of \(\mathcal{M}_K\) is much closer to the mode than for \(\mathcal{N}_K\) (because \(r < \sqrt{K}\)), the mode is not unequivocally a member of the typical set. In fact, the definition of typical sets sort of breaks down for this distribution, because we need to allow for a very large range of probability densities to capture the bulk of its mass. In this sense, it behaves a lot more like the one-dimensional Gaussian. Nevertheless, even this strange concoction of a distribution exhibits unintuitive behaviour in high-dimensional space!
If you would like to cite this post in an academic context, you can use this BibTeX snippet:
@misc{dieleman2020typicality,
author = {Dieleman, Sander},
title = {Musings on typicality},
url = {https://benanne.github.io/2020/09/01/typicality.html},
year = {2020}
}
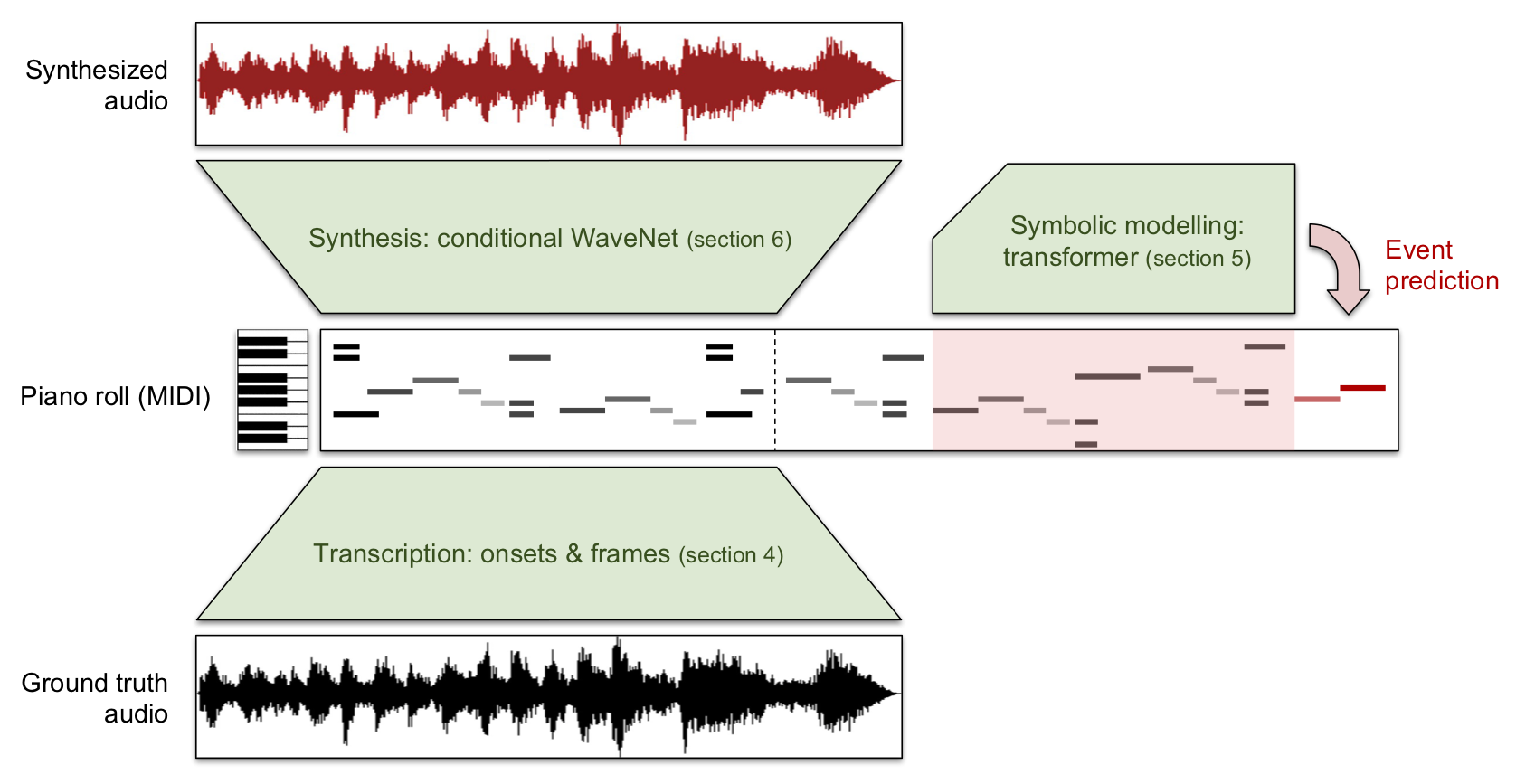
In November last year, I co-presented a tutorial on waveform-based music processing with deep learning with Jordi Pons and Jongpil Lee at ISMIR 2019. Jongpil and Jordi talked about music classification and source separation respectively, and I presented the last part of the tutorial, on music generation in the waveform domain. It was very well received, so I’ve decided to write it up in the form of a blog post.
ISMIR used to be my home conference when I was a PhD student working on music information retrieval, so it was great to be back for the first time in five years. With about 450 attendees (the largest edition yet), it made for a very different experience than what I’m used to with machine learning conferences like ICML, NeurIPS and ICLR, whose audiences tend to number in the thousands these days.
Our tutorial on the first day of the conference gave rise to plenty of interesting questions and discussions throughout, which inspired me to write some of these things down and hopefully provide a basis to continue these discussions online. Note that I will only be covering music generation in this post, but Jordi and Jongpil are working on blog posts about their respective parts. I will share them here when they are published. In the meantime, the slide deck we used includes all three parts and is now available on Zenodo (PDF) and on Google slides. I’ve also added a few things to this post that I’ve thought of since giving the tutorial, and some new work that has come out since.
This is also an excellent opportunity to revive my blog, which has lain dormant for the past four years. I have taken the time to update the blog software, so if anything looks odd, that may be why. Please let me know so I can fix it!
Presenting our tutorial session at ISMIR 2019 in Delft, The Netherlands. Via ISMIR2019 on Twitter.
Overview
This blog post is divided into a few different sections. I’ll try to motivate why modelling music in the waveform domain is an interesting problem. Then I’ll give an overview of generative models, the various flavours that exist, and some important ways in which they differ from each other. In the next two sections I’ll attempt to cover the state of the art in both likelihood-based and adversarial models of raw music audio. Finally, I’ll raise some observations and discussion points. If you want to skip ahead, just click the section title below to go there.
Note that this blog post is not intended to provide an exhaustive overview of all the published research in this domain – I have tried to make a selection and I’ve inevitably left out some great work. Please don’t hesitate to suggest relevant work in the comments section!
Motivation
Why audio?
Music generation has traditionally been studied in the symbolic domain: the output of the generative process could be a musical score, a sequence of MIDI events, a simple melody, a sequence of chords, a textual representation1 or some other higher-level representation. The physical process through which sound is produced is abstracted away. This dramatically reduces the amount of information that the models are required to produce, which makes the modelling problem more tractable and allows for lower-capacity models to be used effectively.
A very popular representation is the so-called piano roll, which dates back to the player pianos of the early 20th century. Holes were punched into a roll of paper to indicate which notes should be played at which time. This representation survives in digital form today and is commonly used in music production. Much of the work on music generation using machine learning has made use of (some variant of) this representation, because it allows for capturing performance-specific aspects of the music without having to model the sound.
Left: player piano with a physical piano roll inside. Right: modern incarnation of a piano roll.
Piano rolls are great for piano performances, because they are able to exactly capture the timing, pitch and velocity (i.e. how hard a piano key is pressed, which is correlated with loudness, but not equivalent to it) of the notes. They are able to very accurately represent piano music, because they cover all the “degrees of freedom” that a performer has at their disposal. However, most other instruments have many more degrees of freedom: think about all the various ways you can play a note on the guitar, for example. You can decide which string to use, where to pick, whether to bend the string or not, play vibrato, … you could even play harmonics, or use two-hand tapping. Such a vast array of different playing techniques endows the performer with a lot more freedom to vary the sound that the instrument produces, and coming up with a high-level representation that can accurately capture all this variety is much more challenging. In practice, a lot of this detail is ignored and a simpler representation is often used when generating music for these instruments.
Modelling the sound that an instrument produces is much more difficult than modelling (some of) the parameters that are controlled by the performer, but it frees us from having to manually design high-level representations that accurately capture all these parameters. Furthermore, it allows our models to capture variability that is beyond the performer’s control: the idiosyncracies of individual instruments, for example (no two violins sound exactly the same!), or the parameters of the recording setup used to obtain the training data for our models. It also makes it possible to model ensembles of instruments, or other sound sources altogether, without having to fundamentally change anything about the model apart from the data it is trained on.
Digital audio representations require a reasonably high bit rate to achieve acceptable fidelity however, and modelling all these bits comes with a cost. Music audio models will necessarily have to have a much higher capacity than their symbolic counterparts, which implies higher computational requirements for model training.
Why waveforms?
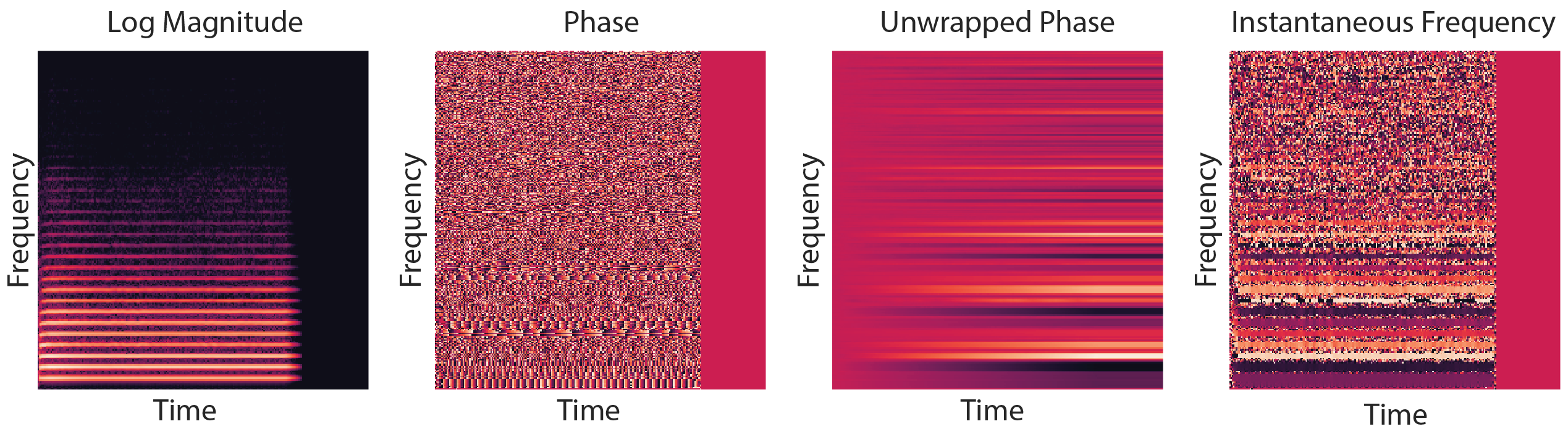
Digital representations of sound come in many shapes and forms. For reproduction, sound is usually stored by encoding the shape of the waveform as it changes over time. For analysis however, we often make use of spectrograms, both for computational methods and for visual inspection by humans. A spectrogram can be obtained from a waveform by computing the Fourier transform of overlapping windows of the signal, and stacking the results into a 2D array. This shows the local frequency content of the signal over time.
Spectrograms are complex-valued: they represent both the amplitude and the phase of different frequency components at each point in time. Below is a visualisation of a magnitude spectrogram and its corresponding phase spectrogram. While the magnitude spectrogram clearly exhibits a lot of structure, with sustained frequencies manifesting as horizontal lines and harmonics showing up as parallel horizontal lines, the phase spectrogram looks a lot more random.
Top: magnitude spectrogram of a piano recording. Bottom: the corresponding phase spectrogram.
When extracting information from audio signals, it turns out that we can often just discard the phase component, because it is not informative for most of the things we could be interested in. In fact, this is why the magnitude spectrogram is often referred to simply as “the spectrogram”. When generating sound however, phase is very important because it meaningfully affects our perception. Listen below to an original excerpt of a piano piece, and a corresponding excerpt where the original phase has been replaced by random uniform phase information. Note how the harmony is preserved, but the timbre changes completely.
Left: excerpt with original phase. Right: the same excerpt with random phase.
The phase component of a spectrogram is tricky to model for a number of reasons:
it is an angle: \(\phi \in [0, 2 \pi)\) and it wraps around;
it becomes effectively random as the magnitude tends towards 0, because noise starts to dominate;
absolute phase is less meaningful, but relative phase differences over time matter perceptually.
If we model waveforms directly, we are implicitly modelling their phase as well, but we don’t run into these issues that make modelling phase so cumbersome. There are other strategies to avoid these issues, some of which I will discuss later, but waveform modelling currently seems to be the dominant approach in the generative setting. This is particularly interesting because magnitude spectrograms are by far the most common representation used for discriminative models of audio.
Discretising waveforms
When representing a waveform digitally, we need to discretise it in both time and amplitude. This is referred to as pulse code modulation (PCM). Because audio waveforms are effectively band-limited (humans cannot perceive frequencies above ~20 kHz), the sampling theorem tells us that we can discretise the waveform in time without any loss of information, as long as the sample rate is high enough (twice the highest frequency). This is why CD quality audio has a sample rate of 44.1 kHz. Much lower sample rates result in an audible loss of fidelity, but since the resulting discrete sequences also end up being much shorter, a compromise is often struck in the context of generative modelling to reduce computational requirements. Most models from literature use sample rates of 16 or 24 kHz.
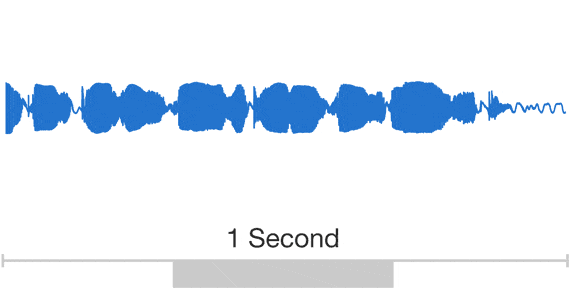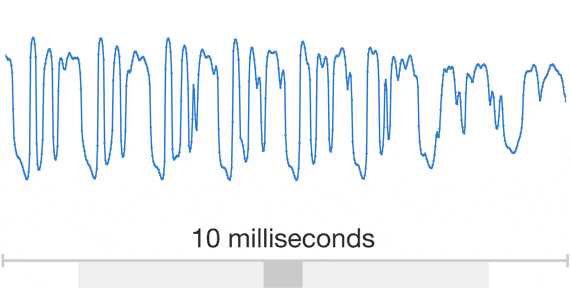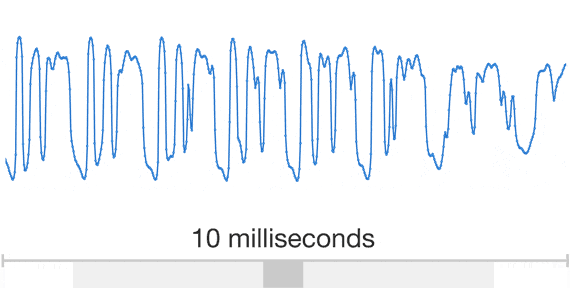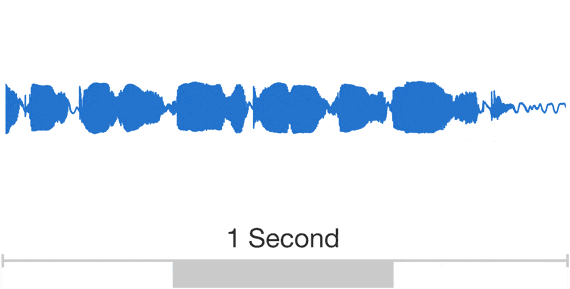
Digital waveform. The individual samples become visible as the zoom level increases. Figure taken from the original WaveNet blog post.
When we also quantise the amplitude, some loss of fidelity is inevitable. CD quality uses 16 bits per sample, representing 216 equally spaced quantisation levels. If we want to use fewer bits, we can use logarithmically spaced quantisation levels instead to account for our nonlinear perception of loudness. This “mu-law companding” will result in a smaller perceived loss of fidelity than if the levels were equally spaced.
Generative models
Given a dataset \(X\) of examples \(x \in X\), which we assume to have been drawn independently from some underlying distribution \(p_X(x)\), a generative model can learn to approximate this distribution \(p_X(x)\). Such a model could be used to generate new samples that look like they could have been part of the original dataset. We distinguish implicit and explicit generative models: an implicit model can produce new samples \(x \sim p_X(x)\), but cannot be used to infer the likelihood of an example (i.e. we cannot tractably compute \(p_X(x)\) given \(x\)). If we have an explicit model, we can do this, though sometimes only up to an unknown normalising constant.
Conditional generative models
Generative models become more practically useful when we can exert some influence over the samples we draw from them. We can do this by providing a conditioning signal \(c\), which contains side information about the kind of samples we want to generate. The model is then fit to the conditional distribution \(p_X(x \vert c)\) instead of \(p_X(x)\).
Conditioning signals can take many shapes or forms, and it is useful to distinguish different levels of information content. The generative modelling problem becomes easier if the conditioning signal \(c\) is richer, because it reduces uncertainty about \(x\). We will refer to conditioning signals with low information content as sparse conditioning, and those with high information content as dense conditioning. Examples of conditioning signals in the image domain and the music audio domain are shown below, ordered according to density.
Examples of sparse and dense conditioning signals in the image domain (top) and the music audio domain (bottom).
Note that the density of a conditioning signal is often correlated with its level of abstraction: high-level side information tends to be more sparse. Low-level side information isn’t necessarily dense, though. For example, we could condition a generative model of music audio on a low-dimensional vector that captures the overall timbre of an instrument. This is a low-level aspect of the audio signal, but it constitutes a sparse conditioning signal.
Likelihood-based models
Likelihood-based models directly parameterise \(p_X(x)\). The parameters \(\theta\) are then fit by maximising the likelihood of the data under the model:
Note that this is typically done in the log-domain because it simplifies computations and improves numerical stability. Because the model directly parameterises \(p_X(x)\), we can easily infer the likelihood of any \(x\), so we get an explicit model. Three popular flavours of likelihood-based models are autoregressive models, flow-based models and variational autoencoders. The following three subsections provide a brief overview of each.
Autoregressive models
In an autoregressive model, we assume that our examples \(x \in X\) can be treated as sequences \(\{x_i\}\). We then factorise the distribution into a product of conditionals, using the chain rule of probability:
\[p_X(x) = \prod_i p(x_i \vert x_{<i}) .\]
These conditional distributions are typically scalar-valued and much easier to model. Because we further assume that the distribution of the sequence elements is stationary, we can share parameters and use the same model for all the factors in this product.
For audio signals, this is a very natural thing to do, but we can also do this for other types of structured data by arbitrarily choosing an order (e.g. raster scan order for images, as in PixelRNN2 and PixelCNN3).
Autoregressive models are attractive because they are able to accurately capture correlations between the different elements \(x_i\) in a sequence, and they allow for fast inference (i.e. computing \(p_X(x)\) given \(x\)). Unfortunately they tend to be slow to sample from, because samples need to be drawn sequentially from the conditionals for each position in the sequence.
Flow-based models
Another strategy for constructing a likelihood-based model is to use the change of variables theorem to transform \(p_X(x)\) into a simple, factorised distribution \(p_Z(z)\) (standard Gaussian is a popular choice) using an invertible mapping \(x = g(z)\):
Here, \(J\) is the Jacobian of \(g(z)\). Models that use this approach are referred to as normalising flows or flow-based models45. They are fast both for inference and sampling, but the requirement for \(g(z)\) to be invertible significantly constrains the model architecture, and it makes them less parameter-efficient. In other words: flow-based models need to be quite large to be effective.
By far the most popular class of likelihood-based generative models, I can’t avoid mentioning variational6 autoencoders7 – but in the context of waveform modelling, they are probably the least popular approach. In a VAE, we jointly learn two neural networks: an inference network \(q(z \vert x)\) learns to probabilistically map examples \(x\) into a latent space, and a generative network \(p(x \vert z)\) learns the distribution of the data conditioned on a latent representation \(z\). These are trained to maximise a lower bound on \(p_X(x)\), called the ELBO (Evidence Lower BOund), because computing \(p_X(x)\) given \(x\) (exact inference) is not tractable.
Typical VAEs assume a factorised distribution for \(p(x \vert z)\), which limits the extent to which they can capture dependencies in the data. While this is often an acceptable trade-off, in the case of waveform modelling it turns out to be a problematic restriction in practice. I believe this is why not a lot of work has been published that takes this approach (if you know of any, please point me to it). VAEs can also have more powerful decoders with fewer assumptions (autoregressive decoders, for example), but this may introduce other issues such as posterior collapse8.
Generative Adversarial Networks9 (GANs) take a very different approach to capturing the data distribution. Two networks are trained simultaneously: a generator \(G\) attempts to produce examples according to the data distribution \(p_X(x)\), given latent vectors \(z\), while a discriminator \(D\) attempts to tell apart generated examples and real examples. In doing so, the discriminator provides a learning signal for the generator which enables it to better match the data distribution. In the original formulation, the loss function is as follows:
The generator is trained to minimise this loss, whereas the discriminator attempts to maximise it. This means the training procedure is a two-player minimax game, rather than an optimisation process, as it is for most machine learning models. Balancing this game and keeping training stable has been one of the main challenges for this class of models. Many alternative formulations have been proposed to address this.
While adversarial and likelihood-based models are both ultimately trying to model \(p_X(x)\), they approach this target from very different angles. As a result, GANs tend to be better at producing realistic examples, but worse at capturing the full diversity of the data distribution, compared to likelihood-based models.
More exotic flavours
Many other strategies to learn models of complicated distributions have been proposed in literature. While research on waveform generation has chiefly focused on the two dominant paradigms of likelihood-based and adversarial models, some of these alternatives may hold promise in this area as well, so I want to mention a few that I’ve come across.
Energy-based models measure the “energy” of examples, and are trained by fitting the model parameters so that examples coming from the dataset have low energy, whereas all other configurations of inputs have high energy. This amounts to fitting an unnormalised density. A nice recent example is the work by Du & Mordatch at OpenAI10. Energy-based models have been around for a very long time though, and one could argue that likelihood-based models are a special case.
Optimal transport is another approach to measure the discrepancy between probability distributions, which has served as inspiration for new variants of generative adversarial networks11 and autoencoders12.
Autoregressive implicit quantile networks13 use a similar network architecture as likelihood-based autoregressive models, but they are trained using the quantile regression loss, rather than maximimum likelihood.
Two continuous distributions can be matched by minimising the L2 distance between the gradients of the density functions with respect to their inputs: \(\mathcal{L}(x) = \mathbb{E} [\vert\vert \nabla_x \log p_X(x) - \nabla_y \log p_Y(y) \vert\vert ^2]\). This is called score matching14 and some recent works have revisited this idea for density estimation15 and generative modelling16.
Please share any others that I haven’t mentioned in the comments!
Mode-covering vs. mode-seeking behaviour
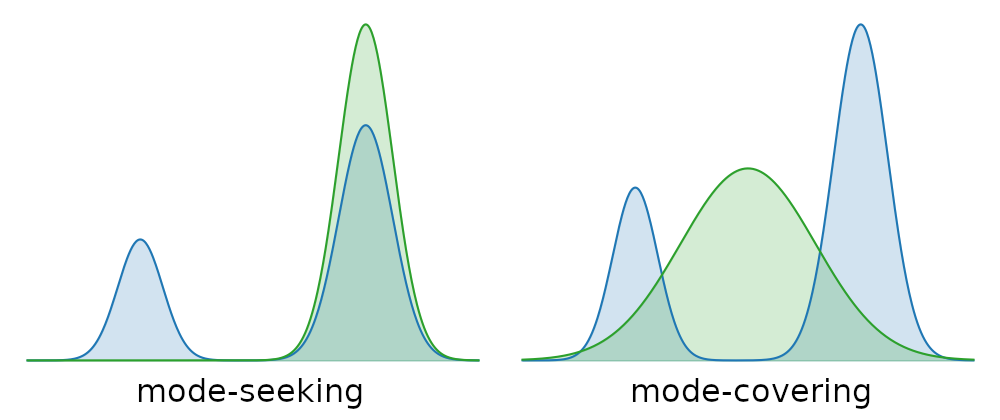
An important consideration when determining which type of generative model is appropriate for a particular application, is the degree to which it is mode-covering or mode-seeking. When a model does not have enough capacity to capture all the variability in the data, different compromises can be made. If all examples should be reasonably likely under the model, it will have to overgeneralise and put probability mass on interpolations of examples that may not be meaningful (mode-covering). If there is no such requirement, the probability mass can be focused on a subset of examples, but then some parts of the distribution will be ignored by the model (mode-seeking).
Illustration of mode-seeking and mode-covering behaviour in model fitting. The blue density represents the data distribution. The green density is our model, which is a single Gaussian. Because the data distribution is multimodal, our model does not have enough capacity to accurately capture it.
Likelihood-based models are usually mode-covering. This is a consequence of the fact that they are fit by maximising the joint likelihood of the data. Adversarial models on the other hand are typically mode-seeking. A lot of ongoing research is focused on making it possible to control the trade-off between these two behaviours directly, without necessarily having to switch the class of models that are used.
In general, mode-covering behaviour is desirable in sparsely conditioned applications, where we want diversity or we expect a certain degree of “creativity” from the model. Mode-seeking behaviour is more useful in densely-conditioned settings, where most of the variability we care about is captured in the conditioning signal, and we favour realism of the generated output over diversity.
Likelihood-based models of waveforms
In this section, I’ll try to summarise some of the key results from the past four years obtained with likelihood-based models of waveforms. While this blog post is supposed to be about music, note that many of these developments were initially targeted at generating speech, so inevitably I will also be talking about some work in the text-to-speech (TTS) domain. I recommend reading the associated papers and/or blog posts to find out more about each of these works.
WaveNet & SampleRNN
Animation showing sampling from a WaveNet model. The model predicts the distribution of potential signal values for each timestep, given past signal values.
WaveNet17 and SampleRNN18 are autoregressive models of raw waveforms. While WaveNet is a convolutional neural network, SampleRNN uses a stack of recurrent neural networks. Both papers appeared on arXiv in late 2016 with only a few months in between, signalling that autoregressive waveform-based audio modelling was an idea whose time had come. Before then, this idea had not been seriously considered, as modelling long-term correlations in sequences across thousands of timesteps did not seem feasible with the tools that were available at that point. Furthermore, discriminative models of audio all used spectral input representations, with only a few works investigating the use of raw waveforms in this setting (and usually with worse results).
Although these models have their flaws (including slow sampling due to autoregressivity, and a lack of interpretability w.r.t. what actually happens inside the network), I think they constituted an important existence proof that encouraged further research into waveform-based models.
WaveNet’s strategy to deal with long-term correlations is to use dilated convolutions: successive convolutional layers use filters with gaps between their inputs, so that the connectivity pattern across many layers forms a tree structure (see figure above). This enables rapid growth of the receptive field, which means that a WaveNet with only a few layers can learn dependencies across many timesteps. Note that the convolutions used in WaveNet are causal (no connectivity from future to past), which forces the model to learn to predict what values the signal could take at each position in time.
SampleRNN’s strategy is a bit different: multiple RNNs are stacked on top of each other, with each running at a different frequency. Higher-level RNNs update less frequently, which means they can more easily capture long-range correlations and learn high-level features.
Both models demonstrated excellent text-to-speech results, surpassing the state of the art at the time (concatenative synthesis, for most languages) in terms of naturalness. Both models were also applied to (piano) music generation, which constituted a nice demonstration of the promise of music generation in the waveform domain, but they were clearly limited in their ability to capture longer-term musical structure.
Sampling from autoregressive models of raw audio can be quite slow and impractical. To address this issue, Parallel WaveNet19 uses probability density distillation to train a model from which samples can be drawn in a single feed-forward pass. This requires a trained autoregressive WaveNet, which functions as a teacher, and an inverse autoregressive flow (IAF) model which acts as the student and learns to mimic the teacher’s predictions.
While an autoregressive model is slow to sample from, inferring the likelihood of a given example (and thus, maximum-likelihood training) can be done in parallel. For an inverse autoregressive flow, it’s the other way around: sampling is fast, but inference is slow. Since most practical applications rely on sampling rather than inference, such a model is often better suited. IAFs are hard to train from scratch though (because that requires inference), and the probability density distillation approach makes training them tractable.
Due to the nature of the probability density distillation objective, the student will end up matching the teacher’s predictions in a way that minimises the reverse KL divergence. This is quite unusual: likelihood-based models are typically trained to minimise the forward KL divergence instead, which is equivalent to maximising the likelihood (and minimising the reverse KL is usually intractable). While minimising the forward KL leads to mode-covering behaviour, minimising the reverse KL will instead lead to mode-seeking behaviour, which means that the model may end up ignoring certain modes in the data distribution.
In the text-to-speech (TTS) setting, this may actually be exactly what we want: given an excerpt of text, we want the model to generate a realistic utterance corresponding to that excerpt, but we aren’t particularly fussed about being able to generate every possible variation – one good-sounding utterance will do. This is a setting where realism is clearly more important than diversity, because all the diversity that we care about is already captured in the conditioning signal that we provide. This is usually the setting where adversarial models excel, because of their inherent mode-seeking behaviour, but using probability density distillation we can also train likelihood-based models this way.
To prevent the model from collapsing, parallel WaveNet uses a few additional loss terms to encourage the produced waveforms to resemble speech (such as a loss on the average power spectrum).
If we want to do music generation, we will typically care more about diversity because the conditioning signals we provide to the model are weaker. I believe this is why we haven’t really seen the Parallel WaveNet approach catch on outside of TTS.
ClariNet20 was introduced as a variant of Parallel WaveNet which uses a Gaussian inverse autoregressive flow. The Gaussian assumption makes it possible to compute the reverse KL in closed form, rather than having to approximate it by sampling, which stabilises training.
Training an IAF with probability density distillation isn’t the only way to train a flow-based model: most can be trained by maximum likelihood instead. In that case, the models will be encouraged to capture all the modes of the data distribution. This, in combination with their relatively low parameter efficiency (due to the invertibility requirement), means that they might need to be a bit larger to be effective. On the other hand, they allow for very fast sampling because all timesteps can be generated in parallel, so while the computational cost may be higher, sampling will still be faster in practice. Another advantage is that no additional loss terms are required to prevent collapse.
WaveGlow21 and FloWaveNet22, both originally published in late 2018, are flow-based models of raw audio conditioned on mel-spectrograms, which means they can be used as vocoders. Because of the limited parameter efficiency of flow-based models, I suspect that it would be difficult to use them for music generation in the waveform domain, where conditioning signals are much more sparse – but they could of course be used to render mel-spectrograms generated by some other model into waveforms (more on that later).
WaveFlow23 (with an F instead of a G) is a more recent model that improves parameter efficiency by combining the flow-based modelling approach with partial autoregressivity to model local signal structure. This allows for a trade-off between sampling speed and model size. Blow24 is a flow-based model of waveforms for non-parallel voice conversion.
For the purpose of music generation, WaveNet is limited by its ability to capture longer-term signal structure, as previously stated. In other words: while it is clearly able to capture local signal structure very well (i.e. the timbre of an instrument), it isn’t able to model the evolution of chord progressions and melodies over longer time periods. This makes the outputs produced by this model sound rather improvisational, to put it nicely.
This may seem counterintuitive at first: the tree structure of the connectivity between the layers of the model should allow for a very rapid growth of its receptive field. So if you have a WaveNet model that captures up to a second of audio at a time (more than sufficient for TTS), stacking a few more dilated convolutional layers on top should suffice to grow the receptive field by several orders of magnitude (up to many minutes). At that point, the model should be able to capture any kind of meaningful musical structure.
In practice, however, we need to train models on excerpts of audio that are at least as long as the longest-range correlations that we want to model. So while the depth of the model has to grow only logarithmically as we increase the desired receptive field, the computational and memory requirements for training do in fact grow linearly. If we want to train a model that can learn about musical structure across tens of seconds, that will necessarily be an order of magnitude more expensive – and WaveNets that generate music already have to be quite large as it is, even with a receptive field of just one second, because music is harder to model than speech. Note also that one second of audio corresponds to a sequence of 16000 timesteps at 16 kHz, so even at a scale of seconds, we are already modelling very long sequences.
In 10 years, the hardware we would need to train a WaveNet with a receptive field of 30 seconds (or almost half a million timesteps at 16 kHz) may just fit in a desktop computer, so we could just wait until then to give it a try. But if we want to train such models today, we need a different strategy. If we could train separate models to capture structure at different timescales, we could have a dedicated model that focuses on capturing longer-range correlations, without having to also model local signal structure. This seems feasible, seeing as models of high-level representations of music (i.e. scores or MIDI) clearly do a much better job of capturing long-range musical structure already.
We can approach this as a representation learning problem: to decouple learning of local and large-scale structure, we need to extract a more compact, high-level representation \(h\) from the audio signals \(x\), that makes abstraction of local detail and has a much lower sample rate. Ideally, we would learn a model \(h = f(x)\) to extract such a representation from data (although using existing high-level representations like MIDI is also possible, as we’ll discuss later).
Then we can split up the task by training two separate models: a WaveNet that models the high-level representation: \(p_H(h)\), and another that models the local signal structure, conditioned on the high-level representation: \(p_{X \vert H}(x \vert h)\). The former model can focus on learning about long-range correlations, as local signal structure is not present in the representation it operates on. The latter model, on the other hand, can focus on learning about local signal structure, as relevant information about large-scale structure is readily available in its conditioning signal. Combined together, these models can be used to sample new audio signals by first sampling \(\hat{h} \sim p_H(h)\) and then \(\hat{x} \sim p_{X \vert H}(x \vert \hat{h})\).
We can learn both \(f(x)\) and \(p_{X \vert H}(x \vert h)\) together by training an autoencoder: \(f(x)\) is the encoder, a feed-forward neural network, and \(p_{X \vert H}(x \vert h)\) is the decoder, a conditional WaveNet. Learning these jointly will enable \(f(x)\) to adapt to the WaveNet, so that it extracts information that the WaveNet cannot easily model itself.
To make the subsequent modelling of \(h = f(x)\) with another WaveNet easier, we use a VQ-VAE25: an autoencoder with a discrete bottleneck. This has two important consequences:
Autoregressive models seem to be more effective on discrete sequences than on continuous ones. Making the high-level representation discrete makes the hierarchical modelling task much easier, as we don’t need to adapt the WaveNet model to work with continuous data.
The discreteness of the representation also limits its information capacity, forcing the autoencoder to encode only the most important information in \(h\), and to use the autoregressive connections in the WaveNet decoder to capture any local structure that wasn’t encoded in \(h\).
To split the task into more than two parts, we can apply this procedure again to the high-level representation \(h\) produced by the first application, and repeat this until we get a hierarchy with as many levels as desired. Higher levels in the hierarchy make abstraction of more and more of the low-level details of the signal, and have progressively lower sample rates (yielding shorter sequences). a three-level hierarchy is shown in the diagram below. Note that each level can be trained separately and in sequence, thus greatly reducing the computational requirements of training a model with a very large receptive field.
Hierarchical WaveNet model, consisting of (conditional) autoregressive models of several levels of learnt discrete representations.
My colleagues and I explored this idea and trained hierachical WaveNet models on piano music26. We found that there was a trade-off between audio fidelity and long-range coherence of the generated samples. When more model capacity was repurposed to focus on long-range correlations, this reduced the capability of the model to capture local structure, resulting in lower perceived audio quality. We also conducted a human evaluation study where we asked several listeners to rate both the fidelity and the musicality of some generated samples, to demonstrate that hierarchical models produce samples which sound more musical.
As alluded to earlier, rather than learning high-level representations of music audio from data, we could also use existing high-level representations such as MIDI to construct a hierarchical model. We can use a powerful language model to model music in the symbolic domain, and also construct a conditional WaveNet model that generates audio, given a MIDI representation. Together with my colleagues from the Magenta team at Google AI, we trained such models on a new dataset called MAESTRO, which features 172 hours of virtuosic piano performances, captured with fine alignment between note labels and audio waveforms27. This dataset is available to download for research purposes.
Compared to hierarchical WaveNets with learnt intermediate representations, this approach yields much better samples in terms of musical structure, but it is limited to instruments and styles of music that MIDI can accurately represent. Manzelli et al. have demonstrated this approach for a few instruments other than piano28, but the lack of available aligned data could pose a problem.
Wave2Midi2Wave: a transcription model to go from audio to MIDI, a transformer to model MIDI sequences and a WaveNet to synthesise audio given a MIDI sequence.
OpenAI introduced the Sparse Transformer model29, a large transformer30 with a sparse attention mechanism that scales better to long sequences than traditional attention (which is quadratic in the length of the modelled sequence). They demonstrated impressive results autoregressively modelling language, images, and music audio using this architecture, with sparse attention enabling their model to cope with waveforms of up to 65k timesteps (about 5 seconds at 12 kHz). The sparse attention mechanism seems like a good alternative to the stacked dilated convolutions of WaveNets, provided that an efficient implementation is available.
An interesting conditional waveform modelling problem is that of “music translation” or “music style transfer”: given a waveform, render a new waveform where the same music is played by a different instrument. The Universal Music Translation Network31 tackles this by training an autoencoder with multiple WaveNet decoders, where the encoded representation is encouraged to be agnostic to the instrument of the input (using an adversarial loss). A separate decoder is trained for each target instrument, so once this representation is extracted from a waveform, it can be synthesised in an instrument of choice. The separation is not perfect, but it works surprisingly well in practice. I think this is a nice example of a model that combines ideas from both likelihood-based models and the adversarial learning paradigm.
Dadabots are a researcher / artist duo who have trained SampleRNN models on various albums (primarily metal) in order to produce more music in the same vein. These models aren’t great at capturing long-range correlations, so it works best for artists whose style is naturally a bit disjointed. Below is a 24 hour livestream they’ve set up with a model generating infinite technical death metal in the style of ‘Relentless Mutation’ by Archspire.
Adversarial models of waveforms
Adversarial modelling of audio has only recently started to see some successes, which is why this section is going to be a lot shorter than the previous one on likelihood-based models. The adversarial paradigm has been extremely successful in the image domain, but researchers have had a harder time translating that success to other domains and modalities, compared to likelihood-based models. As a result, published work so far has primarily focused on speech generation and the generation of individual notes or very short clips of music. As a field, we are still very much in the process of figuring out how to make GANs work well for audio at scale.
WaveGAN
One of the first works to attempt using GANs for modelling raw audio signals is WaveGAN32. They trained a GAN on single-word speech recordings, bird vocalisations, individual drum hits and short excerpts of piano music. They also compared their raw audio-based model with a spectrogram-level model called SpecGAN. Although the fidelity of the resulting samples is far from perfect in some cases, this work undoubtedly inspired a lot of researchers to take audio modelling with GANs more seriously.
So far in this blog post, we have focused on generating audio waveforms directly. However, I don’t want to omit GANSynth33, even though technically speaking it does not operate directly in the waveform domain. This is because the spectral representation it uses is exactly invertible – no other models or phase reconstruction algorithms are used to turn the spectograms it generates into waveforms, which means it shares a lot of the advantages of models that operate directly in the waveform domain.
As discussed before, modelling the phase component of a complex spectrogram is challenging, because the phase of real audio signals can seem essentially random. However, using some of its unique characteristics, we can transform the phase into a quantity that is easier to model and reason about: the instantaneous frequency. This is obtained by computing the temporal difference of the unwrapped phase between subsequent frames. “Unwrapping” means that we shift the phase component by a multiple of \(2 \pi\) for each frame as needed to make it monotonic over time, as shown in the diagram below (because phase is an angle, all values modulo \(2 \pi\) are equivalent).
The instantaneous frequency captures how much the phase of a signal moves from one spectrogram frame to the next. For harmonic sounds, this quantity is expected to be constant over time, as the phase rotates at a constant velocity. This makes this representation particularly suitable to model musical sounds, which have a lot of harmonic content (and in fact, it might also make the representation less suitable for modelling more general classes of audio signals, though I don’t know if anyone has tried). For harmonic sounds, the instantaneous frequency is almost trivial to predict.
GANSynth is an adversarial model trained to produce the magnitude and instantaneous frequency spectrograms of recordings of individual musical notes. The trained model is also able to generalise to sequences of notes to some degree. Check out the blog post for sound examples and more information.
Top: waveform with specrogram frame boundaries indicated as dotted lines. Middle: from phase to instantaneous frequency. Bottom: visualisations of the magnitude, phase, unwrapped phase and instantaneous frequency spectra of a real recording of a note.
Two recent papers demonstrate excellent results using GANs for text-to-speech: MelGAN34 and GAN-TTS35. The former also includes some music synthesis results, although fidelity is still an issue in that domain. The focus of MelGAN is inversion of magnitude spectrograms (potentially generated by other models), whereas as GAN-TTS is conditioned on the same “linguistic features” as the original WaveNet for TTS.
The architectures of both models share some interesting similarities, which shed light on the right inductive biases for raw waveform discriminators. Both models use multiple discriminators at different scales, each of which operates on a random window of audio extracted from the full sequence produced by the generator. This is similar to the patch-based discriminators that have occasionally been used in GANs for image generation. This windowing strategy seems to dramatically improve the capability of the generator to correctly model high frequency content in the audio signals, which is much more crucial to get right for audio than for images because it more strongly affects perceptual quality. The fact that both models benefited from this particular discriminator design indicates that we may be on the way to figuring out how to best design discriminator architectures for raw audio.
There are also some interesting differences: where GAN-TTS uses a combination of conditional and unconditional discriminators, MelGAN uses only unconditional discriminators and instead encourages the generator output to match the ground truth audio by adding an additional feature matching loss: the L1 distance between discriminator feature maps of real and generated audio. Both approaches seem to be effective.
Adversarial waveform synthesis is particularly useful for TTS, because it enables the use of highly parallelisable feed-forward models, which tend to have relatively low capacity requirements because they are trained with a mode-seeking loss. This means the models can more easily be deployed on low-power hardware while still performing audio synthesis in real-time, compared to autoregressive or flow-based models.
To wrap up this blog post, I want to summarise a few thoughts about the current state of this area of research, and where things could be moving next.
Why the emphasis on likelihood in music modelling?
Clearly, the dominant paradigm for generative models of music in the waveform domain is likelihood-based. This stands in stark contrast to the image domain, where adversarial approaches greatly outnumber likelihood-based ones. I suspect there are a few reasons for this (let me know if you think of any others):
Compared to likelihood-based models, it seems like it has been harder to translate the successes of adversarial models in the image domain to other domains, and to the audio domain in particular. I think this is because in a GAN, the discriminator fulfills the role of a domain-specific loss function, and important prior knowledge that guides learning is encoded in its architecture. We have known about good architectural priors for images for a long time (stacks of convolutions), as evidenced by work on e.g. style transfer36 and the deep image prior37. For other modalities, we don’t know as much yet. It seems we are now starting to figure out what kind of architectures work for waveforms (see MelGAN and GAN-TTS, some relevant work has also been done in the discriminative setting38).
Adversarial losses are mode-seeking, which makes them more suitable for settings where realism is more important than diversity (for example, because the conditioning signal contains most of the required diversity, as in TTS). In music generation, which is primarily a creative application, diversity is very important. Improving diversity of GAN samples is the subject of intense study right now, but I think it could be a while before they catch up with likelihood-based models in this sense.
The current disparity could also simply be a consequence of the fact that likelihood-based models got a head start in waveform modelling, with WaveNet and SampleRNN appearing on the scene in 2016 and WaveGAN in 2018.
Another domain where likelihood-based models dominate is language modelling. I believe the underlying reasons for this might be a bit different though: language is inherently discrete, and extending GANs to modelling discrete data at scale is very much a work in progress. This is also more likely to be the reason why likelihood-based models are dominant for symbolic music generation as well: most symbolic representations of music are discrete.
Alternatives to modelling waveforms directly
Instead of modelling music in the waveform domain, there are many possible alternative approaches. We could model other representations of audio signals, such as spectrograms, as long as we have a way to obtain waveforms from such representations. We have quite a few options for this:
We could use invertible spectrograms (i.e. phase information is not discarded), but in this case modelling the phase poses a considerable challenge. There are ways to make this easier, such as the instantaneous frequency representation used by GANSynth.
We could also use magnitude spectrograms (as is typically done in discriminative models of audio), and then use a phase reconstruction algorithm such as the Griffin-Lim algorithm39 to infer a plausible phase component, based only on the generated magnitude. This approach was used for the original Tacotron model for TTS40, and for MelNet41, which models music audio autoregressively in the spectrogram domain.
Instead of a traditional phase reconstruction algorithm, we could also use a vocoder to go from spectrograms to waveforms. A vocoder, in this context, is simply a generative model in the waveform domain, conditioned on spectrograms. Vocoding is a densely conditioned generation task, and many of the models discussed before can and have been used as vocoders (e.g. WaveNet in Tacotron 242, flow-based models of waveforms, or MelGAN). This approach has some advantages: generated magnitude spectrograms are often imperfect, and vocoder models can learn to account for these imperfections. Vocoders can also work with inherently lossy spectrogram representations such as mel-spectrograms and constant-Q spectrograms43.
If we are generating audio conditioned on an existing audio signal, we could also simply reuse the phase of the input signal, rather than reconstructing or generating it. This is commonly done in source separation, and the approach could also be used for music style transfer.
That said, modelling spectrograms isn’t always easier than modelling waveforms. Although spectrograms have a much lower temporal resolution, they contain much more information per timestep. In autoregressive models of spectrograms, one would have to condition along both the time and frequency axes to capture all dependencies, which means we end up with roughly as many sequential sampling steps as in the raw waveform case. This is the approach taken by MelNet.
An alternative is to make an assumption of independence between different frequency bands at each timestep, given previous timesteps. This enables autoregressive models to produce entire spectrogram frames at a time. This partial independence assumption turns out to be an acceptable compromise in the text-to-speech domain, and is used in Tacotron and Tacotron 2. Vocoder models are particularly useful here as they can attempt to fix the imperfections resulting from this simplification of the model. I’m not sure if anybody has tried, but I would suspect that this independence assumption would cause more problems for music generation.
An interesting new approach combining traditional signal processing ideas with neural networks is Differentiable Digital Signal Processing (DDSP)44. By creating learnable versions of existing DSP components and incorporating them directly into neural networks, these models are endowed with much stronger inductive biases about sound and music, and can learn to produce realistic audio with fewer trainable parameters, while also being more interpretable. I suspect that this research direction may gain a lot of traction in the near future, not in the least because the authors have made their code publicly available, and also because of its modularity and lower computational requirements.
Diagram of an example DDSP model. The yellow boxes represent differentiable signal processing components. Taken from the original blog post.
Finally, we could train symbolic models of music instead: for many instruments, we already have realistic synthesisers, and we can even train them given enough data (see Wave2Midi2Wave). If we are able to craft symbolic representations that capture the aspects of music we care about, then this is an attractive approach as it is much less computationally intensive. Magenta’s Music Transformer45 and OpenAI’s MuseNet are two models that have recently shown impressive results in this domain, and it is likely that other ideas from the language modelling community could bring further improvements.
Generative models of music in the waveform domain have seen substantial progress over the past few years, but the best results so far are still relatively easy to distinguish from real recordings, even at fairly short time scales. There is still a lot of room for improvement, but I believe a lot of this will be driven by better availability of computational resources, and not necessarily by radical innovation on the modelling front – we have great tools already, they are simply a bit expensive to use due to substantial computational requirements. As time goes on and computers get faster, hopefully this task will garner interest as it becomes accessible to more researchers.
One interesting question is whether adversarial models are going to catch up with likelihood-based models in this domain. I think it is quite likely that GANs, having recently made in-roads in the densely conditioned setting, will gradually be made to work for more sparsely conditioned audio generation tasks as well. Fully unconditional generation with long-term coherence seems very challenging however, and I suspect that the mode-seeking behaviour of the adversarial loss will make this much harder to achieve. A hybrid model, where a GAN captures local signal structure and another model with a different objective function captures high-level structure and long-term correlations, seems like a sensible thing to build.
Hierarchy is a very important prior for music (and, come to think of it, for pretty much anything else we like to model), so models that explicitly incorporate this are going to have a leg up on models that don’t – at the cost of some additional complexity. Whether this additional complexity will always be worth it remains to be seen, but at the moment, this definitely seems to be the case.
At any rate, splitting up the problem into multiple stages that can be solved separately has been fruitful, and I think it will continue to be. So far, hierarchical models (with learnt or handcrafted intermediate representations) and spectrogram-based models with vocoders have worked well, but perhaps there are other ways to “divide and conquer”. A nice example of a different kind of split in the image domain is the one used in Subscale Pixel Networks46, where separate networks model the most and least significant bits of the image data.
Conclusion
If you made it to the end of this post, congratulations! I hope I’ve convinced you that music modelling in the waveform domain is an interesting research problem. It is also very far from a solved problem, so there are lots of opportunities for interesting new work. I have probably missed a lot of relevant references, especially when it comes to more recent work. If you know about relevant work that isn’t discussed here, feel free to share it in the comments! Questions about this blog post and this line of research are very welcome as well.
Van den Oord, Li, Babuschkin, Simonyan, Vinyals, Kavukcuoglu, van den Driessche, Lockhart, Cobo, Stimberg, Casagrande, Grewe, Noury, Dieleman, Elsen, Kalchbrenner, Zen, Graves, King, Walters, Belov and Hassabis, “Parallel WaveNet: Fast High-Fidelity Speech Synthesis”, International Conference on Machine Learning, 2018. ↩
Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin, “Attention is All you Need”, Advances in neural information processing systems 30 (NeurIPS), 2017. ↩
This post is another collaboration with Jan Schlüter from the OFAI (@f0k on GitHub), a fellow MIR researcher and one of the lead developers of Lasagne. He recently added a cool new feature that we wanted to highlight: enabling the use of arbitrary Theano expressions as layer parameters.
As many of you probably know, Jan Schlüter and I are part of the team that develops Lasagne, a lightweight neural network library built on top of Theano.
One of the key design principles of Lasagne is transparency: we try not to hide Theano or numpy behind an additional layer of abstractions and encapsulation, but rather expose their functionality and data types and try to follow their conventions. This makes it very easy to learn how to use Lasagne if you already know how to use Theano – there just isn’t all that much extra to learn. But most importantly, it allows you to easily mix and match parts of Lasagne with vanilla Theano code. This is the way Lasagne is meant to be used.
In keeping with this philosophy, Jan recently added a feature that we’ve been discussing early on in designing the API (#11): it allows any learnable layer parameter to be specified as a mathematical expression evaluating to a correctly-shaped tensor. Previously, layer parameters had to be Theano shared variables, i.e., naked tensors to be learned directly. This new feature makes it possible to constrain network parameters in various, potentially creative ways. Below, we’ll go through a few examples of what is now possible that wasn’t before.
Default case
Let’s create a simple fully-connected layer of 500 units on top of an input layer of 784 units.
Autoencoders with tied weights are a common use case, and until now implementing them in Lasagne was a bit tricky. Weight sharing in Lasagne has always been easy and intuitive:
l2=DenseLayer(l1,num_units=500)l3=DenseLayer(l1,num_units=500,W=l2.W)# l2 and l3 now share the same weight matrix!
… but in an autoencoder, you want the weights of the decoding layer to be the transpose of the weights of the encoding layer. So you would do:
… but that didn’t work before: l2.W.T is a Theano expression, but not a Theano shared variable as was expected. This is counter-intuitive, and indeed, people expected it to work and were disappointed to find out that it didn’t. With the new feature this is no longer true. The above will work just fine. Yay!
Factorized weights
To reduce the number of parameters in your network (e.g. to prevent overfitting), you could force large parameter matrices to be low-rank by factorizing them. In our example from before, we could factorize the 784x500 weight matrix into the product of a 784x100 and a 100x500 matrix. The number of weights of the layer then goes down from 392000 to 128400 (not including the biases).
You could also use T.softplus(w) instead of T.exp(w). You might also be tempted to try sticking a ReLU in there (T.maximum(w, 0)), but note that applying the linear rectifier to the weight matrix would lead to many of the underlying weights getting stuck at negative values, as the linear rectifier has zero gradient for negative inputs!
Positive semi-definite weights
There are plenty of other creative uses, such as constraining weights to be positive semi-definite (for whatever reason):
There are only a couple of limitations to using Theano expressions as layer parameters. One is that Lasagne functions and methods such as Layer.get_params() will implicitly assume that any shared variable featuring in these Theano expressions is to be treated as a parameter. In practice that means you can’t mix learnable and non-learnable parameter variables in a single expression. Also, the same tags will apply to all shared variables in an expression. More information about parameter tags can be found in the documentation.
For almost all use cases, these limitations should not be an issue. If they are, your best bet is to implement a custom layer class. Luckily, this is also very easy in Lasagne.
Why it works
All of this is made possible because Lasagne builds on Theano, which takes care of backpropagating through the parameter expression to any underlying learned tensors. In frameworks building on hard-coded layer implementations rather than an automatic expression compiler, all these examples would require writing custom backpropagation code.
If you want to play around with this yourself, try the bleeding-edge version of Lasagne. You can find installation instructions here.
Have fun experimenting! If you’ve done something cool that you’d like to share, feel free to send us a pull request on our Recipes repository.